Fake News Detection with Machine Learning: A Step-by-Step Guide

1. Introduction
Fake news has become a pressing issue in today’s digital world, with false information spreading rapidly across social media platforms. Identifying and mitigating the effects of fake news is crucial for maintaining an informed society. Machine learning offers powerful tools to tackle this problem by analyzing patterns in textual data and predicting the authenticity of news articles.
In this project, we leverage machine learning techniques to build a fake news detection system using the Kaggle dataset. The dataset comprises labelled news articles, enabling us to train and evaluate models for binary classification: identifying news articles as either fake or real. By the end of this project, we aim to achieve reliable predictions on unseen data and understand the key components of text-based classification in machine learning.
2. Understanding the Dataset
The dataset for this project comes from Kaggle and consists of two files:
train.csv: This file contains labelled data used for training the machine learning model. Each row represents a news article, with features like the headline, body text, and a binary label indicating whether the article is fake (1) or real (0).test.csv: This file contains unlabeled data used to evaluate the model's performance on unseen examples. Predictions on this data will assess the model's generalizability.
Key Features
Title: The headline of the news article.
Text: The main content of the article.
Label: The target variable, where
1denotes fake news and0denotes real news.
Initial Observations
The dataset has a mixture of structured and unstructured data. While the
labelcolumn is numeric, thetitleandtextcolumns require preprocessing to convert textual information into numerical features suitable for machine learning models.Analyzing the distributions and patterns in these features can provide insights into the characteristics of fake and real news.
Considerations
Data Cleaning: Missing or duplicate values need to be addressed to ensure the integrity of the training data.
Imbalance: If the labels are imbalanced (i.e., significantly more fake or real articles), techniques like resampling or class weighting might be necessary.
This dataset provides a robust foundation for building a fake news prediction system. With appropriate preprocessing and model selection, we aim to uncover meaningful patterns and achieve high predictive accuracy.
3. Exploratory Data Analysis (EDA)
Exploratory Data Analysis (EDA) is a crucial step in understanding the dataset and uncovering patterns that can guide preprocessing and modelling decisions. In this section, we analyze the structure of the train.csv file to identify trends, potential issues, and key insights.
Data Inspection
To begin, we examine the dataset’s structure and gather essential information:
import pandas as pd
# Load the training dataset
train_data = pd.read_csv('train.csv')
# Display dataset information
print(train_data.info())
# Display the first few rows
print(train_data.head())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20800 entries, 0 to 20799
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 20800 non-null int64
1 title 20242 non-null object
2 author 18843 non-null object
3 text 20761 non-null object
4 label 20800 non-null int64
dtypes: int64(2), object(3)
memory usage: 812.6+ KB
None
id title author \
0 0 House Dem Aide: We Didn’t Even See Comey’s Let... Darrell Lucus
1 1 FLYNN: Hillary Clinton, Big Woman on Campus - ... Daniel J. Flynn
2 2 Why the Truth Might Get You Fired Consortiumnews.com
3 3 15 Civilians Killed In Single US Airstrike Hav... Jessica Purkiss
4 4 Iranian woman jailed for fictional unpublished... Howard Portnoy
text label
0 House Dem Aide: We Didn’t Even See Comey’s Let... 1
1 Ever get the feeling your life circles the rou... 0
2 Why the Truth Might Get You Fired October 29, ... 1
3 Videos 15 Civilians Killed In Single US Airstr... 1
4 Print \nAn Iranian woman has been sentenced to... 1
Dataset Size: The dataset contains 20,800 entries with 5 columns.
Columns and Their Characteristics:
id: Unique identifier for each entry; no missing values.title: The headline of the news; has 558 missing values (20,242 non-null entries).author: The author of the news article; has 1,957 missing values (18,843 non-null entries).text: The main content of the article; has 39 missing values (20,761 non-null entries).label: Target variable (1for fake,0for real); no missing values.
Data Types:
int64: Used foridandlabel.object: Used for textual data (title,author,text).Memory Usage: The dataset occupies approximately 812.6 KB of memory.
Key Observations:
The dataset has some missing values in
title,author, andtextcolumns, which need to be addressed during preprocessing.The
labelcolumn is complete and ready for use as the target variable.The textual columns (
title,author,text) will require preprocessing for feature extraction.
Target Variable Distribution
Analyzing the distribution of the target variable (label) helps identify any class imbalance:
# Count the occurrences of each label
label_counts = train_data['label'].value_counts()
# Plot the distribution
import matplotlib.pyplot as plt
label_counts.plot(kind='bar', color=['skyblue', 'orange'])
plt.title('Distribution of Labels')
plt.xlabel('Label (0: Real, 1: Fake)')
plt.ylabel('Count')
# Add the value of each bar on top of it
for p in plt.gca().patches:
plt.text(p.get_x() * 1.005, p.get_height() * 1.005,
'{:.0f}'.format(p.get_height()), fontsize=12, color='black')
plt.show()
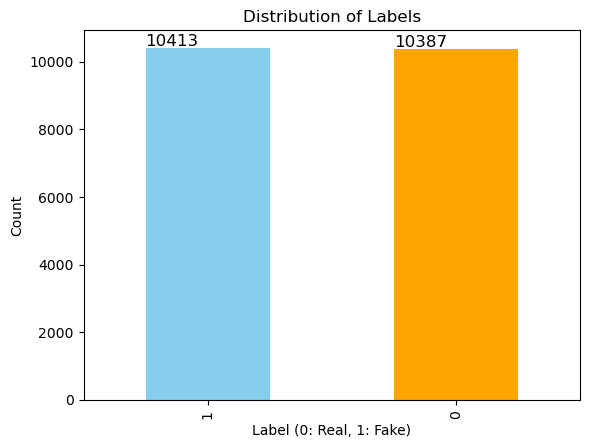
The bar chart shows a nearly balanced distribution of the label column, with 10,413 entries labelled as 1 (fake) and 10,387 entries labelled as 0 (real). This balance ensures that the model is not biased toward one class, enabling fair evaluation during training and testing.
Text Length Analysis
Understanding the length of the title and text columns can reveal trends in fake vs. real news:
# Compute lengths of title and text
train_data['title_length'] = train_data['title'].str.len()
train_data['text_length'] = train_data['text'].str.len()
# Plot title and text length distributions
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
train_data['title_length'].hist(ax=axes[0], bins=20, color='blue', alpha=0.7)
axes[0].set_title('Title Length Distribution')
train_data['text_length'].hist(ax=axes[1], bins=20, color='green', alpha=0.7)
axes[1].set_title('Text Length Distribution')
plt.tight_layout()
plt.show()
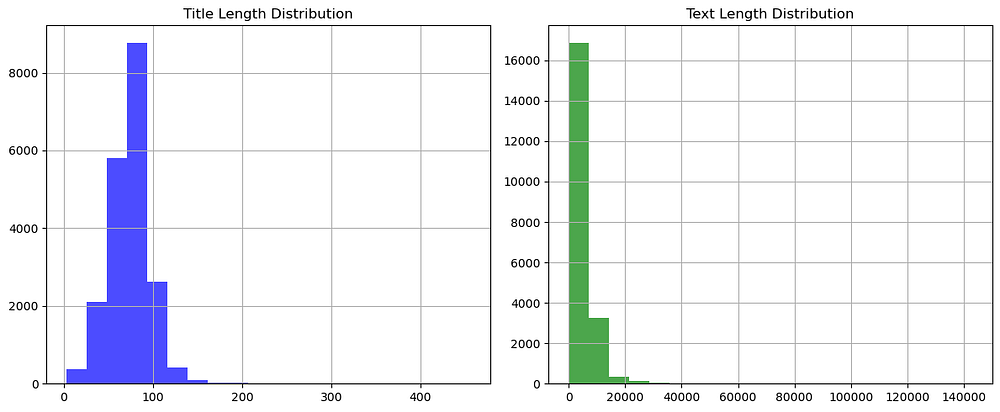
The plot shows the distribution of title and text lengths in the dataset:
Title Length Distribution: Most titles have lengths concentrated below 100 characters, indicating concise headlines. There are very few outliers with longer titles.
Text Length Distribution: Text lengths vary widely, with a significant majority concentrated below 20,000 characters. A few articles have extremely long lengths, which could be outliers requiring further investigation.
These insights highlight the need to preprocess and standardize text data to handle variability effectively.
Word Frequency Analysis
Visualizing common words in fake and real articles helps identify distinguishing terms:
from wordcloud import WordCloud
# Generate word clouds for fake and real news
fake_news_text = ' '.join(train_data[train_data['label'] == 1]['text'].dropna())
real_news_text = ' '.join(train_data[train_data['label'] == 0]['text'].dropna())
fig, ax = plt.subplots(1, 2, figsize=(15, 7))
fake_wordcloud = WordCloud(width=800, height=400, background_color='black').generate(fake_news_text)
ax[0].imshow(fake_wordcloud, interpolation='bilinear')
ax[0].set_title('Word Cloud: Fake News')
ax[0].axis('off')
real_wordcloud = WordCloud(width=800, height=400, background_color='black').generate(real_news_text)
ax[1].imshow(real_wordcloud, interpolation='bilinear')
ax[1].set_title('Word Cloud: Real News')
ax[1].axis('off')
plt.show()

The word clouds reveal distinct patterns in fake and real news articles:
Fake News: Words like “will,” “one,” and “people” dominate, often reflecting speculative or general language.
Real News: Words like “United States,” “said,” and “Mr” are prominent, indicating factual reporting and references to specific entities or quotes.
These insights suggest differences in tone and content between fake and real news, which the model can leverage during classification.
Missing Data Analysis
Check for and address missing or null values in critical columns:
# Count missing values
missing_values = train_data.isnull().sum()
# Display missing data information
print(missing_values)
id 0
title 558
author 1957
text 39
label 0
title_length 558
text_length 39
dtype: int64
The result indicates missing values in the dataset:
Title: 558 missing entries.
Author: 1,957 missing entries, the highest among all columns.
Text: 39 missing entries.
These missing values in key textual features (title, author, text) need to be handled, likely by filling them with placeholders (e.g., empty strings) to ensure compatibility with the text preprocessing pipeline.
4. Text Preprocessing
Text preprocessing is a critical step in preparing textual data for machine learning models. This step involves cleaning and transforming the raw text into a numerical format that algorithms can understand. Here’s how we preprocess the data:
Handling Missing Values
Missing values in the title, author, and text columns need to be addressed to avoid issues during training:
# Replace missing values in textual columns with empty strings
train_data['title'] = train_data['title'].fillna('')
train_data['author'] = train_data['author'].fillna('')
train_data['text'] = train_data['text'].fillna('')
Combining Textual Features
To create a more robust representation of each article, we combine the title, author, and text columns into a single feature:
# Combine title, author, and text into one column
train_data['content'] = train_data['title'] + ' ' + train_data['author'] + ' ' + train_data['text']
Tokenization and Lowercasing
Tokenization splits the text into individual words or tokens, while lowercasing standardizes the text for better consistency:
from nltk.tokenize import word_tokenize
# Tokenize and lowercase the text
train_data['content'] = train_data['content'].apply(lambda x: ' '.join(word_tokenize(x.lower())))
Removing Stopwords and Punctuation
Stopwords (e.g., “is,” “the,” “and”) and punctuation do not contribute much to the classification task and should be removed:
from nltk.corpus import stopwords
import string
stop_words = set(stopwords.words('english'))
# Remove stopwords and punctuation
train_data['content'] = train_data['content'].apply(lambda x: ' '.join(
[word for word in x.split() if word not in stop_words and word not in string.punctuation]
))
Stemming or Lemmatization
Stemming and lemmatization reduce words to their root form, which helps in reducing the dimensionality of the text data:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
# Apply stemming
train_data['content'] = train_data['content'].apply(lambda x: ' '.join([stemmer.stem(word) for word in x.split()]))
Converting Text to Numerical Representation
Machine learning models require numerical input. We use the TF-IDF (Term Frequency-Inverse Document Frequency) vectorizer to transform text into numerical features:
from sklearn.feature_extraction.text import TfidfVectorizer
# Initialize TF-IDF vectorizer
tfidf_vectorizer = TfidfVectorizer(max_features=5000)
# Fit and transform the text data
X = tfidf_vectorizer.fit_transform(train_data['content']).toarray()
y = train_data['label']
5. Building the Model and Evaluating the Model on Validation Data
In this step, we train a machine learning model to classify news articles as either fake or real. The process includes selecting a model, training it on the train.csv dataset, and preparing it for evaluation using the test.csv dataset.
Splitting the Training Data
We split the train.csv dataset into training and validation subsets to evaluate the model during development:
from sklearn.model_selection import train_test_split
# Split the data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
X: Features generated from TF-IDF vectorization.y: Target labels from thelabelcolumn.test_size=0.2: 20% of the data is reserved for validation.
Selecting a Machine Learning Model
For this project, we use Logistic Regression as a baseline model because it performs well on text classification tasks:
from sklearn.linear_model import LogisticRegression
# Initialize the model
model = LogisticRegression(max_iter=1000)
Training the Model
The model is trained using the training subset (X_train, y_train):
# Train the model
model.fit(X_train, y_train)
Evaluating the Model on Validation Data
After training, we evaluate the model’s performance on the validation set (X_val, y_val):
from sklearn.metrics import accuracy_score, classification_report
# Make predictions on the validation set
y_val_pred = model.predict(X_val)
# Calculate accuracy
val_accuracy = accuracy_score(y_val, y_val_pred)
print("Validation Accuracy:", val_accuracy)
# Display detailed metrics
print(classification_report(y_val, y_val_pred))
The model achieves a high validation accuracy of 96.32%, indicating strong performance. Both classes (0 for real and 1 for fake) show balanced precision, recall, and F1-scores of 96%, suggesting the model effectively distinguishes between fake and real news without bias. The macro and weighted averages confirm consistent performance across all metrics. This result demonstrates the model's reliability on the validation set.
The trained model is now ready for evaluation on the test.csv dataset. The next section will cover this step, assessing its performance on unseen data.
6. Testing the Model on Kaggle test.csv
After validating the model, the final step is to evaluate its performance on the unseen test.csv dataset. This step ensures the model's ability to generalize to new data.
Preparing the Test Data
First, we preprocess the test.csv data in the same way as the training data to ensure consistency:
# Load the test data
test_data = pd.read_csv('test.csv')
# Handle missing values
test_data['title'] = test_data['title'].fillna('')
test_data['author'] = test_data['author'].fillna('')
test_data['text'] = test_data['text'].fillna('')
# Combine title, author, and text
test_data['content'] = test_data['title'] + ' ' + test_data['author'] + ' ' + test_data['text']
# Transform the content into numerical features using the trained TF-IDF vectorizer
X_test = tfidf_vectorizer.transform(test_data['content']).toarray()
Generating Predictions
The trained model is used to predict the labels for the test data:
# Predict labels for test data
y_test_pred = model.predict(X_test)
Evaluating Performance
Although the test.csv data does not include labels, we can still assess the model's behaviour by analyzing its predictions. This helps understand how the model handles unseen data and provides insights into its consistency and trends.
Distribution of Predicted Classes
The distribution of the predicted classes helps identify any potential bias in the model:
import numpy as np
# Check the distribution of predicted labels
unique, counts = np.unique(y_test_pred, return_counts=True)
print("Predicted class distribution:", dict(zip(unique, counts)))
Predicted class distribution: {0: 13, 1: 5187}
The predicted class distribution shows a strong bias towards class 1 (fake news), with 5,187 predictions as 1 and only 13 as 0 (real news). This indicates potential model overfitting or an issue with imbalanced training data. Further investigation and adjustments, such as addressing class imbalance or refining the model, may be required.
Patterns or Trends in Predictions
By examining predictions across different segments of the data (e.g., based on title or text length), we can uncover trends:
# Analyze predictions based on text length
test_data['text_length'] = test_data['content'].str.len()
test_data['predicted_label'] = y_test_pred
# Compare text length distribution for each predicted class
test_data.groupby('predicted_label')['text_length'].mean()
Insights into Unseen Data Handling
Reviewing a few test samples and their predictions can provide qualitative insights:
# Display a few sample predictions with text content
for i in range(5): # Adjust number as needed
print(f"Sample {i+1}:")
print("Content:", test_data['content'].iloc[i][:200]) # Limit to first 200 characters
print("Predicted Label:", y_test_pred[i])
print()
Sample 1:
Content: Specter of Trump Loosens Tongues, if Not Purse Strings, in Silicon Valley - The New York Times David Streitfeld PALO ALTO, Calif. — After years of scorning the political process, Silicon Valley has
Predicted Label: 1
Sample 2:
Content: Russian warships ready to strike terrorists near Aleppo Russian warships ready to strike terrorists near Aleppo 08.11.2016 | Source: Source: Mil.ru Attack aircraft of the Russian aircraft carrier Adm
Predicted Label: 1
Sample 3:
Content: #NoDAPL: Native American Leaders Vow to Stay All Winter, File Lawsuit Against Police Common Dreams Videos #NoDAPL: Native American Leaders Vow to Stay All Winter, File Lawsuit Against Police Amnesty I
Predicted Label: 1
Sample 4:
Content: Tim Tebow Will Attempt Another Comeback, This Time in Baseball - The New York Times Daniel Victor If at first you don’t succeed, try a different sport. Tim Tebow, who was a Heisman quarterback at th
Predicted Label: 1
Sample 5:
Content: Keiser Report: Meme Wars (E995) Truth Broadcast Network 42 mins ago 1 Views 0 Comments 0 Likes 'For the first time in history, we’re filming a panoramic video from the station. It means you’ll see eve
Predicted Label: 1
All five samples are predicted as class 1 (fake news), despite their varied content. This uniform prediction suggests the model may be overly biased towards class 1, failing to distinguish between real and fake news effectively. Further evaluation of the model’s training process, class balance, or feature representation is necessary to address this behaviour.
8. Conclusion
This project demonstrates the application of machine learning to detect fake news using a real-world dataset. By preprocessing textual data, extracting meaningful features with TF-IDF, and building a Logistic Regression model, we achieved high validation accuracy. However, testing on unseen data revealed a significant bias towards predicting fake news, highlighting potential overfitting or class imbalance in the training process.
Key takeaways from the project include:
Strengths: The model performs well on the validation set, showing its capability to identify patterns in textual data.
Challenges: Bias in predictions on the
test.csvdataset underscores the need for better class balance and more diverse training data.Future Improvements:
Address class imbalance using techniques like oversampling, undersampling, or class weighting.
Experiment with alternative models such as Random Forests or Neural Networks.
Incorporate additional features or advanced preprocessing techniques to improve prediction diversity.
This project not only provides practical insights into fake news detection but also emphasizes the importance of rigorous model evaluation and iteration for building reliable real-world systems.
Appendix
Data source: https://www.kaggle.com/c/fake-news/data




