Building a Robust Credit Card Fraud Detection Model with Machine Learning

1. Introduction
Credit card fraud is a significant challenge for the financial industry, with billions of dollars lost annually to fraudulent transactions. Machine learning provides a powerful tool for detecting and preventing such fraud by identifying patterns that human analysis might miss. This project demonstrates a comprehensive approach to building a machine learning model for credit card fraud detection.
While based on an original tutorial, this article introduces several enhancements to improve the project’s robustness and scalability. These include:
Analyzing feature relevance and importance to ensure only impactful features are used.
Automating the training process with reusable functions for cleaner and more readable code.
Incorporating hyperparameter tuning to optimize model performance.
Pipelining the entire workflow for efficiency and reproducibility.
By addressing these aspects, this project aims to build a robust fraud detection model and highlight best practices in machine learning projects.
2. Dataset Overview
The project uses the creditcard.csv dataset, which contains transactions made by European cardholders over two days. The dataset consists of 284,807 transactions, of which 492 are labelled as fraudulent (0.172% of the data), making it highly imbalanced.
Key Features:
Time: The seconds elapsed between the first transaction in the dataset and each subsequent transaction.
Amount: Transaction amount, scaled for privacy but indicative of potential fraud.
V1, V2, …, V28: Principal components obtained using PCA (Principal Component Analysis) to protect sensitive information.
Class: Target variable indicating whether a transaction is fraudulent (1) or not (0).
Challenges with the Dataset:
Imbalanced Classes: Fraudulent transactions represent a tiny fraction of the dataset, necessitating techniques to handle class imbalance effectively.
Feature Representation: Many features are transformed, requiring domain knowledge and careful analysis to interpret their contribution to the model.
In this project, we will explore the predictive importance of the Time and Amount features alongside the PCA-transformed features. This will help us determine their impact on model performance and efficiency, laying a strong foundation for building an effective fraud detection system.
3. Exploratory Data Analysis (EDA)
Before diving into model building, it is essential to conduct Exploratory Data Analysis (EDA) to understand the dataset’s structure, identify patterns, and address potential issues like class imbalance. Below are the key steps and observations from the EDA process.
Dataset Structure
Start by examining the dataset’s shape and a summary of its contents.
import pandas as pd
# Load the dataset
df = pd.read_csv('creditcard.csv')
# Display dataset structure
print(df.info())
print(df.describe())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 284807 entries, 0 to 284806
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Time 284807 non-null float64
1 V1 284807 non-null float64
2 V2 284807 non-null float64
3 V3 284807 non-null float64
4 V4 284807 non-null float64
5 V5 284807 non-null float64
6 V6 284807 non-null float64
7 V7 284807 non-null float64
8 V8 284807 non-null float64
9 V9 284807 non-null float64
10 V10 284807 non-null float64
11 V11 284807 non-null float64
12 V12 284807 non-null float64
13 V13 284807 non-null float64
14 V14 284807 non-null float64
15 V15 284807 non-null float64
16 V16 284807 non-null float64
17 V17 284807 non-null float64
18 V18 284807 non-null float64
19 V19 284807 non-null float64
20 V20 284807 non-null float64
21 V21 284807 non-null float64
22 V22 284807 non-null float64
23 V23 284807 non-null float64
24 V24 284807 non-null float64
25 V25 284807 non-null float64
26 V26 284807 non-null float64
27 V27 284807 non-null float64
28 V28 284807 non-null float64
29 Amount 284807 non-null float64
30 Class 284807 non-null int64
dtypes: float64(30), int64(1)
memory usage: 67.4 MB
None
Time V1 V2 V3 V4 \
count 284807.000000 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05
mean 94813.859575 1.168375e-15 3.416908e-16 -1.379537e-15 2.074095e-15
std 47488.145955 1.958696e+00 1.651309e+00 1.516255e+00 1.415869e+00
min 0.000000 -5.640751e+01 -7.271573e+01 -4.832559e+01 -5.683171e+00
25% 54201.500000 -9.203734e-01 -5.985499e-01 -8.903648e-01 -8.486401e-01
50% 84692.000000 1.810880e-02 6.548556e-02 1.798463e-01 -1.984653e-02
75% 139320.500000 1.315642e+00 8.037239e-01 1.027196e+00 7.433413e-01
max 172792.000000 2.454930e+00 2.205773e+01 9.382558e+00 1.687534e+01
V5 V6 V7 V8 V9 \
count 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05
mean 9.604066e-16 1.487313e-15 -5.556467e-16 1.213481e-16 -2.406331e-15
std 1.380247e+00 1.332271e+00 1.237094e+00 1.194353e+00 1.098632e+00
min -1.137433e+02 -2.616051e+01 -4.355724e+01 -7.321672e+01 -1.343407e+01
25% -6.915971e-01 -7.682956e-01 -5.540759e-01 -2.086297e-01 -6.430976e-01
50% -5.433583e-02 -2.741871e-01 4.010308e-02 2.235804e-02 -5.142873e-02
75% 6.119264e-01 3.985649e-01 5.704361e-01 3.273459e-01 5.971390e-01
max 3.480167e+01 7.330163e+01 1.205895e+02 2.000721e+01 1.559499e+01
... V21 V22 V23 V24 \
count ... 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05
mean ... 1.654067e-16 -3.568593e-16 2.578648e-16 4.473266e-15
std ... 7.345240e-01 7.257016e-01 6.244603e-01 6.056471e-01
min ... -3.483038e+01 -1.093314e+01 -4.480774e+01 -2.836627e+00
25% ... -2.283949e-01 -5.423504e-01 -1.618463e-01 -3.545861e-01
50% ... -2.945017e-02 6.781943e-03 -1.119293e-02 4.097606e-02
75% ... 1.863772e-01 5.285536e-01 1.476421e-01 4.395266e-01
max ... 2.720284e+01 1.050309e+01 2.252841e+01 4.584549e+00
V25 V26 V27 V28 Amount \
count 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 284807.000000
mean 5.340915e-16 1.683437e-15 -3.660091e-16 -1.227390e-16 88.349619
std 5.212781e-01 4.822270e-01 4.036325e-01 3.300833e-01 250.120109
min -1.029540e+01 -2.604551e+00 -2.256568e+01 -1.543008e+01 0.000000
25% -3.171451e-01 -3.269839e-01 -7.083953e-02 -5.295979e-02 5.600000
50% 1.659350e-02 -5.213911e-02 1.342146e-03 1.124383e-02 22.000000
75% 3.507156e-01 2.409522e-01 9.104512e-02 7.827995e-02 77.165000
max 7.519589e+00 3.517346e+00 3.161220e+01 3.384781e+01 25691.160000
Class
count 284807.000000
mean 0.001727
std 0.041527
min 0.000000
25% 0.000000
50% 0.000000
75% 0.000000
max 1.000000
[8 rows x 31 columns]
- Dataset Shape and Features:
The dataset contains 284,807 entries and 31 columns, all numeric.
Features include 28 PCA-transformed components (
V1toV28),Time,Amount, and the target variableClass.
2. Class Imbalance: The target variable Class is heavily imbalanced, with only 0.172% fraudulent transactions (Class = 1). This necessitates specific techniques like resampling (e.g., SMOTE) or adjusting class weights to handle the imbalance.
3. Feature Details:
Time: Ranges from 0 to 172,792 seconds (~48 hours), likely indicating the relative time of transactions. Its mean and median suggest uniform distribution across the time span.Amount: Has a high skew, with most transactions being low-value (median: 22.0). However, the maximum amount is 25,691.16, suggesting a significant range.
4. PCA Features (V1 to V28):
Mean values are close to 0, consistent with PCA normalization.
Standard deviations vary, indicating different scales for each principal component.
Some PCA components (e.g.,
V7,V17, andV27) show extreme values, potentially representing anomalies or key indicators.
4. No Missing Values: The dataset is clean with no missing values, reducing preprocessing effort.
5. Class:
Mean: 0.001727, confirming the severe imbalance.
Min: 0 and Max: 1, indicating binary classification for fraud detection.
Key Takeaways:
The dataset is clean and ready for preprocessing.
An imbalance in the
Classfeature requires handling to avoid model bias.AmountandTimeshow significant variability, suggesting potential predictive importance but requiring further analysis.PCA-transformed features must be evaluated for their contributions to fraud detection.
Target Variable Distribution
Visualizing the distribution of the target variable (Class) to understand class imbalance.
import matplotlib.pyplot as plt
# Plot the distribution of the target variable
class_counts = df['Class'].value_counts()
plt.figure(figsize=(6, 4))
class_counts.plot(kind='bar', color=['skyblue', 'orange'])
plt.title("Distribution of Fraudulent and Non-Fraudulent Transactions")
plt.xticks([0, 1], ['Non-Fraudulent (0)', 'Fraudulent (1)'], rotation=0)
plt.ylabel("Number of Transactions")
plt.xlabel("Class")
# Annotate the plots with the values
for p in plt.gca().patches:
plt.gca().text(p.get_x() + p.get_width() / 2, p.get_y() + p.get_height() / 2,
'{:,.0f}'.format(p.get_height()), ha="center")
plt.show()
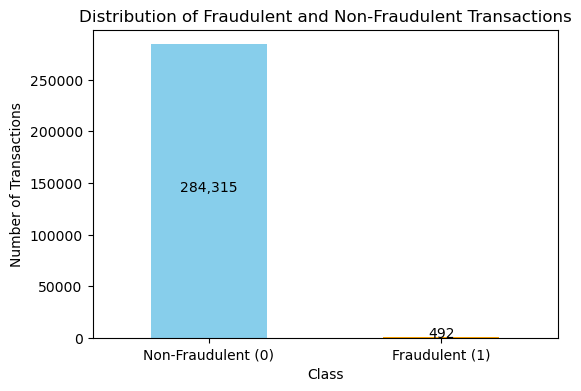
The dataset is highly imbalanced, with fraudulent transactions constituting only 0.172% of the data.
Statistical Summary
Check the range and distribution of key features like Amount and Time.
# Plot histograms for 'Amount' and 'Time'
df[['Amount', 'Time']].hist(bins=30, figsize=(12, 5), color='lightblue', edgecolor='black')
plt.suptitle("Distribution of 'Amount' and 'Time'")
plt.show()
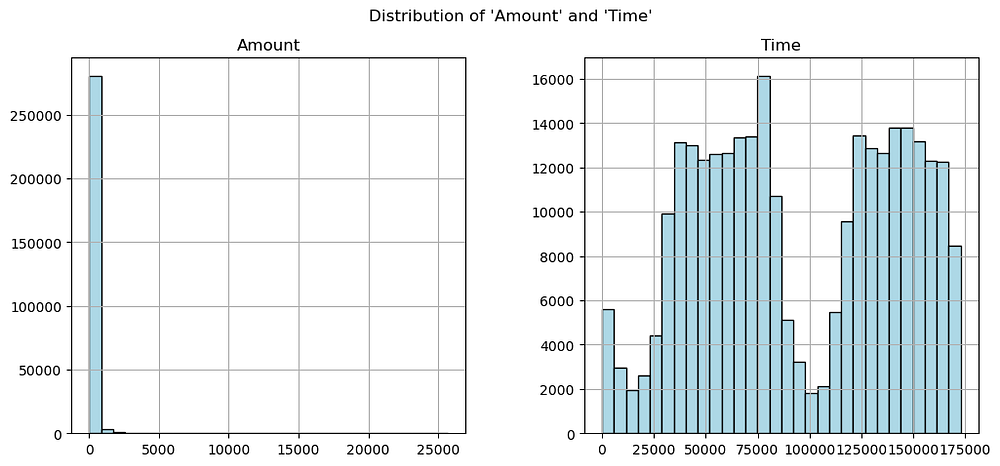
AmountDistribution:
Highly Skewed: Most transactions have very small amounts, with a significant number below $100.
Outliers: A few transactions have very high values, with the maximum exceeding $25,000. These outliers could be important for detecting fraud.
2. Time Distribution: Uniformly Distributed Peaks: The Time feature shows cyclical patterns, with higher transaction frequency at specific intervals, likely corresponding to daily transaction cycles.
Key Insights:
The skewed distribution of
Amountmay require transformation (e.g., log scaling) for better model performance.Timemay capture behavioural patterns related to fraud but requires further feature engineering to extract meaningful insights.
Feature Correlation
Analyze the relationships among features and their correlation with the target variable.
import seaborn as sns
# Compute correlation matrix
correlation_matrix = df.corr()
# Plot the heatmap with annotations
plt.figure(figsize=(14, 10))
sns.heatmap(correlation_matrix, cmap='coolwarm', annot=True, fmt=".2f", linewidths=0.2, annot_kws={'size': 6})
plt.title("Feature Correlation Heatmap")
plt.show()
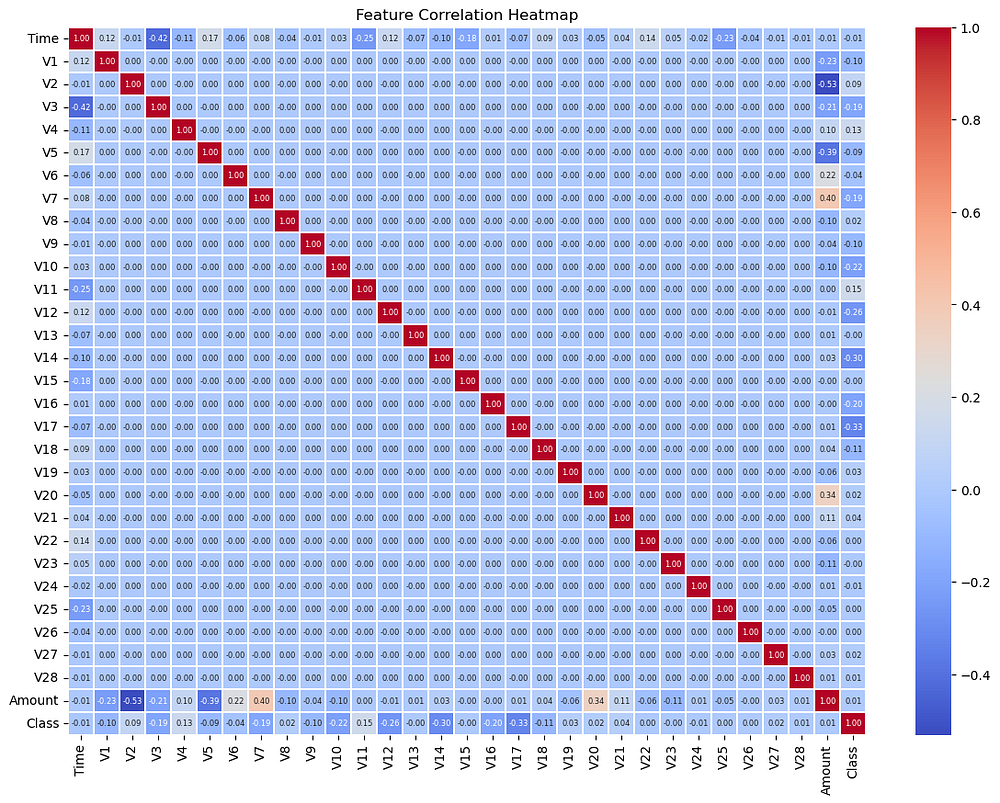
ClassCorrelation:
Class has weak correlations with all features:
The highest positive correlation: 0.26 with
V11.Highest negative correlation: -0.53 with
V17.
Indicates no single feature strongly predicts fraud, necessitating the use of multiple features in the model.
2. Feature Relationships:
Most off-diagonal correlations are close to 0, indicating that PCA-transformed features (
V1toV28) are largely independent of one another, as designed.Exceptions:
V2andV20show some correlation (0.34), which might require further attention.
3. Amount and Time Correlation: Amount and Time are weakly correlated with each other and the target (Class), confirming the need to evaluate their predictive value.
Key Insights:
The dataset’s features are well-separated due to PCA, reducing multicollinearity.
The weak correlation of features with the target suggests that detecting fraud relies on combining multiple features rather than any single predictor.
Insights on Fraudulent Transactions
Focus on differences between fraudulent and non-fraudulent transactions for the Amount and Time features.
1. Transaction Amount by Class:
# Boxplot for 'Amount' by 'Class'
plt.figure(figsize=(8, 6))
sns.boxplot(x='Class', y='Amount', data=df, palette='coolwarm')
plt.title("Transaction Amount Distribution by Class")
plt.show()
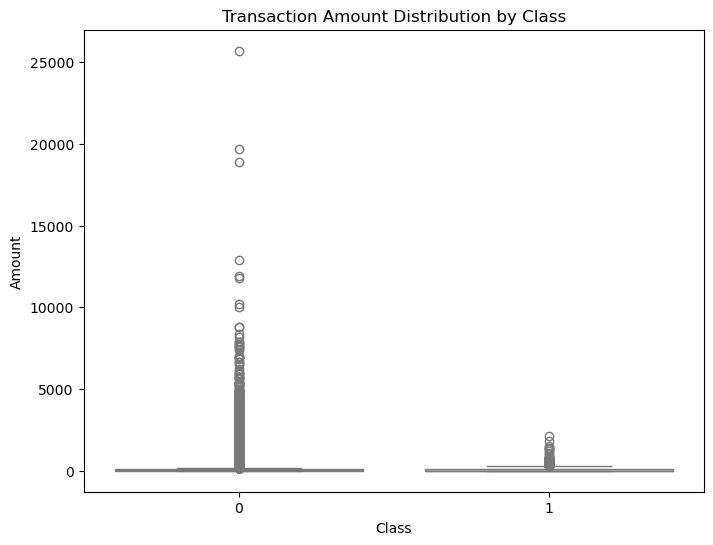
Class 0 (Non-Fraudulent):
Amounts are widely distributed, with a significant number of outliers exceeding $25,000.
Most transactions are clustered at lower amounts, reflecting normal spending behaviour.
Class 1 (Fraudulent):
Amounts are smaller, with fewer outliers compared to non-fraudulent transactions.
Indicates fraudulent transactions tend to involve smaller amounts.
2. Transaction Time by Class:
# Boxplot for 'Time' by 'Class'
plt.figure(figsize=(8, 6))
sns.boxplot(x='Class', y='Time', data=df, palette='coolwarm')
plt.title("Transaction Time Distribution by Class")
plt.show()
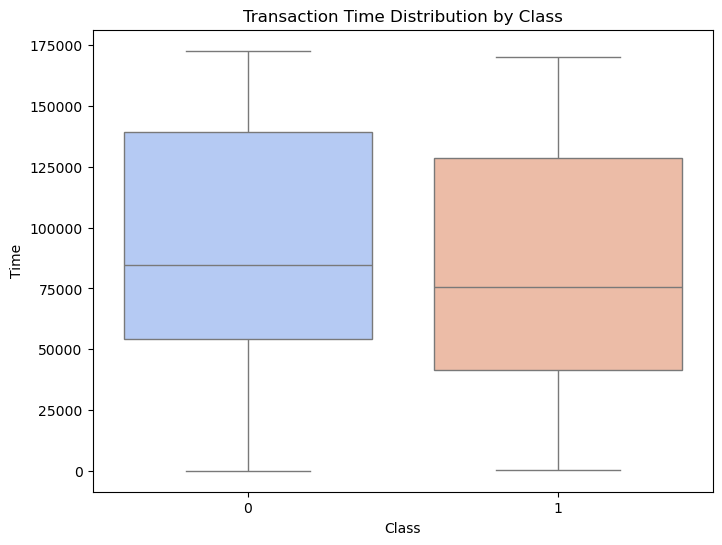
Both classes have similar interquartile ranges and medians.
No strong distinction in transaction times between fraudulent and non-fraudulent transactions.
Suggests
Timemay not have direct predictive power and might require further feature engineering.
Key Insights:
Amountshows potential as a predictive feature due to differing distributions between classes.Timeappears less informative as a standalone feature but could contribute in combination with others.
4. Data Wrangling and Feature Selection
Data wrangling and feature selection are crucial steps in preparing the dataset for modelling. These steps involve ensuring the data is clean, addressing class imbalance, and identifying the most relevant features for predicting fraud.
Handling Class Imbalance
The dataset is highly imbalanced, with only 0.172% of transactions labelled as fraudulent. To address this, we will use the Synthetic Minority Oversampling Technique (SMOTE), which generates synthetic samples for the minority class to balance the dataset.
from imblearn.over_sampling import SMOTE
# Separate features and target
X = df.drop(columns=['Class'])
y = df['Class']
# Apply SMOTE to handle class imbalance
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, y)
# Check the new class distribution
print("Class Distribution After SMOTE:")
print(y_resampled.value_counts())
Class Distribution After SMOTE:
Class
0 284315
1 284315
Name: count, dtype: int64
After SMOTE, the dataset will have an equal number of samples for both classes, ensuring the model learns effectively from both fraudulent and non-fraudulent transactions.
Scaling Features
The Amount and Time features are not PCA-transformed and have different scales. These features need to be scaled to ensure they do not dominate the model due to their magnitude.
from sklearn.preprocessing import RobustScaler
# Apply RobustScaler to scale 'Amount' and 'Time'
scaler = RobustScaler()
df[['Amount', 'Time']] = scaler.fit_transform(df[['Amount', 'Time']])
RobustScaler is used to reduce the influence of outliers, which are present in both the Amount and Time features.
Feature Selection
Feature selection helps to reduce noise and improve model performance by focusing on the most relevant features. We will:
Check Correlation with the Target (
Class): Use the correlation matrix to identify features with a strong relationship toClass.Evaluate Feature Importance: Use tree-based models (e.g., Random Forest) to compute feature importance scores.
Code for Correlation Analysis:
# Compute correlation with the target variable
correlations = df.corr()['Class'].sort_values(ascending=False)
print("Correlation with Class:")
print(correlations)
Correlation with Class:
Class 1.000000
V11 0.154876
V4 0.133447
V2 0.091289
V21 0.040413
V19 0.034783
V20 0.020090
V8 0.019875
V27 0.017580
V28 0.009536
Amount 0.005632
V26 0.004455
V25 0.003308
V22 0.000805
V23 -0.002685
V15 -0.004223
V13 -0.004570
V24 -0.007221
Time -0.012323
V6 -0.043643
V5 -0.094974
V9 -0.097733
V1 -0.101347
V18 -0.111485
V7 -0.187257
V3 -0.192961
V16 -0.196539
V10 -0.216883
V12 -0.260593
V14 -0.302544
V17 -0.326481
Name: Class, dtype: float64
Top Positive Correlations:
V11(0.15),V4(0.13), andV2(0.09) have the strongest positive correlations withClass. These features are likely useful in identifying fraudulent transactions.Top Negative Correlations:
V17(-0.33),V14(-0.30), andV12(-0.26) have the strongest negative correlations. These features also appear significant for detecting fraud.Weakly Correlated Features: Features like
Amount(0.0056) andTime(-0.012) have negligible correlations withClass, suggesting they might not be directly predictive.Near-Zero Correlations: Features like
V22(0.0008) andV23(-0.0027) have near-zero correlations, indicating low relevance to the target variable.
Key Insights:
Features with strong correlations (positive or negative) are likely valuable predictors for fraud detection.
Weakly or near-zero correlated features (e.g.,
V22,V23,Amount,Time) may not contribute significantly and could be candidates for removal after further evaluation (e.g., feature importance analysis).
Code for Feature Importance: (this might take 3–10 minutes)
from sklearn.ensemble import RandomForestClassifier
# Train a Random Forest to compute feature importance
rf = RandomForestClassifier(random_state=42)
rf.fit(X_resampled, y_resampled)
# Extract feature importance
importances = rf.feature_importances_
features = X.columns
# Display feature importance
feature_importance = pd.DataFrame({'Feature': features, 'Importance': importances})
feature_importance = feature_importance.sort_values(by='Importance', ascending=False)
print(feature_importance.head(10))
Feature Importance
14 V14 0.202067
10 V10 0.128370
12 V12 0.117422
4 V4 0.110618
17 V17 0.087035
3 V3 0.074618
11 V11 0.049666
16 V16 0.043178
2 V2 0.038913
9 V9 0.026606
- Top Features:
V14(20.2%) is the most important feature, significantly contributing to the model's predictions.V10(12.8%) andV12(11.7%) also play key roles in distinguishing fraudulent transactions.
2. Moderately Important Features:
Features like
V4(11.1%) andV17(8.7%) hold moderate importance.These features should be retained in the model for accurate predictions.
- Lower Importance Features:
V9(2.7%) andV2(3.9%) are among the least important in this top-10 list but still contribute to the model.
Key Insights:
The model relies heavily on specific PCA components (
V14,V10,V12).Less important features outside the top-10 list may be candidates for removal to improve computational efficiency. Further validation is recommended before dropping them.
Dropping Less Relevant Features
Based on the feature importance analysis, we focus on retaining only the most important features that significantly contribute to the model’s predictions. Features outside the top 10 in importance, or those with negligible contribution, can be dropped to reduce noise and improve computational efficiency.
Features to Retain: Top 10 features based on importance: V14, V10, V12, V4, V17, V3, V11, V16, V2, and V9.
Dropping Low-Importance Features: Features with minimal importance outside this top 10 list will be removed. For example: features like V22, V23, Amount, and Time, which showed low correlations with the target variable (Class), will also be considered for removal.
# Retain only the top 10 features based on importance
top_features = ['V14', 'V10', 'V12', 'V4', 'V17', 'V3', 'V11', 'V16', 'V2', 'V9']
X_resampled = X_resampled[top_features]
This step ensures the model focuses on the most predictive features, reducing dimensionality and improving efficiency without compromising performance. Further evaluation will confirm the impact of this reduction on the model’s accuracy.
5. Model Implementation
In this section, we will build, train, and evaluate machine learning models to predict fraudulent transactions. The focus will be on automating repetitive tasks for improved readability and scalability.
Splitting the Data
The resampled dataset is split into training and testing sets to evaluate model performance on unseen data.
from sklearn.model_selection import train_test_split
# Split the dataset
X_train, X_test, y_train, y_test = train_test_split(X_resampled, y_resampled, test_size=0.3, random_state=42)
print(f"Training set size: {X_train.shape[0]}")
print(f"Testing set size: {X_test.shape[0]}")
Training set size: 398041
Testing set size: 170589
Automating Model Training and Validation
To streamline model training and evaluation, we define a reusable function. This function will:
Train a given model on the training data.
Evaluate the model on the test data using metrics like precision, recall, F1-score, and accuracy.
from sklearn.metrics import classification_report, accuracy_score
def train_and_evaluate_model(model, X_train, X_test, y_train, y_test):
# Train the model
"""
Train a given model on the training set and evaluate its performance on the test set.
Parameters:
model (sklearn estimator): The model to be trained and evaluated.
X_train (pandas DataFrame): The feature DataFrame for the training set.
X_test (pandas DataFrame): The feature DataFrame for the test set.
y_train (pandas Series): The target Series for the training set.
y_test (pandas Series): The target Series for the test set.
Returns:
None
"""
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate the model
print("Model Performance:")
print(classification_report(y_test, y_pred))
print(f"Accuracy: {accuracy_score(y_test, y_pred):.4f}")
Implementing Random Forest
Random Forest is used as the primary model due to its robustness and ability to handle class imbalance effectively.
# Initialize the Random Forest model
rf_model = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)
# Train and evaluate the model
train_and_evaluate_model(rf_model, X_train, X_test, y_train, y_test)
Model Performance:
precision recall f1-score support
0 1.00 1.00 1.00 85149
1 1.00 1.00 1.00 85440
accuracy 1.00 170589
macro avg 1.00 1.00 1.00 170589
weighted avg 1.00 1.00 1.00 170589
Accuracy: 0.9997
The Random Forest model performs exceptionally well, achieving nearly perfect scores across all metrics. It effectively identifies both fraudulent and non-fraudulent transactions with very high precision and recall.
Implementing Logistic Regression
Logistic Regression is included for comparison as a simpler model.
from sklearn.linear_model import LogisticRegression
# Initialize the Logistic Regression model
lr_model = LogisticRegression(max_iter=1000, random_state=42)
# Train and evaluate the model
train_and_evaluate_model(lr_model, X_train, X_test, y_train, y_test)
Model Performance:
precision recall f1-score support
0 0.96 0.99 0.98 85149
1 0.99 0.96 0.97 85440
accuracy 0.97 170589
macro avg 0.98 0.97 0.97 170589
weighted avg 0.98 0.97 0.97 170589
Accuracy: 0.9749
Logistic Regression also performs well but is slightly less effective than Random Forest. It achieves high precision and recall but has minor misclassifications compared to Random Forest.
Performance Comparison Table:
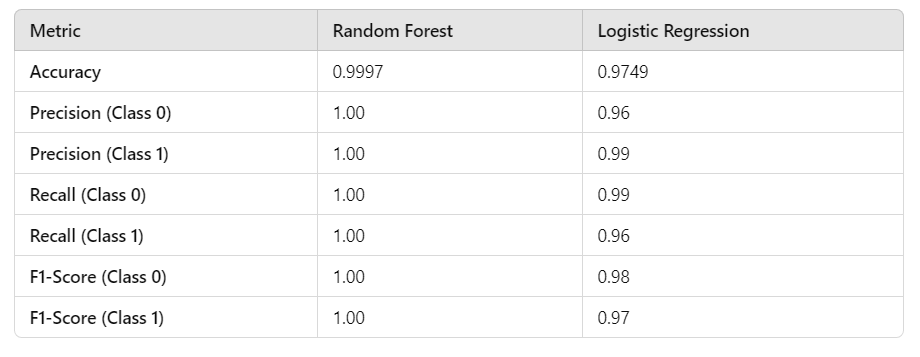
Key Insights:
Random Forest: Achieves near-perfect performance, making it the best choice for this task. However, it may require more computational resources compared to Logistic Regression.
Logistic Regression: Performs well but is slightly less effective than Random Forest, with a lower accuracy and F1-score. It could be a viable alternative for faster predictions on resource-constrained systems.
The next step will involve hyperparameter tuning to further optimize these models for performance and efficiency.
6. Hyperparameter Tuning
Hyperparameter tuning is a critical step to optimize the performance of machine learning models. It involves adjusting the model’s parameters to achieve the best possible balance between accuracy and computational efficiency.
Tuning Random Forest
Tuning the hyperparameters of a Random Forest model can significantly improve its performance. However, hyperparameter tuning, especially with large datasets, can be computationally expensive. Below, we discuss a resource-efficient approach suitable for personal projects while also mentioning the original approach for those with stronger computational resources.
Resource-Efficient Approach: Randomized Search
Instead of performing an exhaustive Grid Search, we use Randomized Search, which samples a specified number of hyperparameter combinations. This reduces computational cost while still exploring the hyperparameter space effectively.
Steps:
Define a smaller hyperparameter space with ranges for the most impactful parameters.
Use
RandomizedSearchCVto sample combinations and test them.
Code:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
# Define the hyperparameter space
param_distributions = {
'n_estimators': [50, 100, 150],
'max_depth': [10, 20, None],
'max_features': ['sqrt', 'log2'],
'min_samples_split': [2, 5, 10]
}
# Initialize the Random Forest model
rf_model = RandomForestClassifier(random_state=42)
# Use Randomized Search with 10 combinations
random_search = RandomizedSearchCV(
estimator=rf_model,
param_distributions=param_distributions,
n_iter=10, # Number of parameter combinations to try
scoring='f1',
cv=3,
random_state=42,
n_jobs=4 # Limit cores for responsiveness
)
# Fit the Randomized Search
random_search.fit(X_train, y_train)
# Display the best parameters
print("Best Parameters from Randomized Search:")
print(random_search.best_params_)
Best Parameters from Randomized Search:
{
'n_estimators': 100,
'max_depth': 20,
'max_features': 'sqrt',
'min_samples_split': 5
}
n_estimators=100: 100 trees strike a balance between performance and computational efficiency. Adding more trees often yields diminishing returns in accuracy.max_depth=20: Depth of 20 is typically sufficient to capture complex patterns in the data without overfitting.max_features='sqrt': Using the square root of the total features per split is a default setting that works well for Random Forests. It reduces overfitting while maintaining predictive power.min_samples_split=5: Increasing the minimum samples required to split a node (default is 2) reduces overfitting and slightly speeds up training.
Original Approach: Grid Search
For those with strong computational resources, Grid Search can be used to test all possible combinations of hyperparameters systematically. This approach may provide slightly better results at the cost of higher computational time.
Code (I didn’t run this code to save the computational time, but you can try it out yourself if you have available resources):
from sklearn.model_selection import GridSearchCV
# Define the parameter grid
param_grid = {
'n_estimators': [50, 100, 150],
'max_depth': [10, 20, None],
'max_features': ['sqrt', 'log2'],
'min_samples_split': [2, 5, 10]
}
# Initialize Grid Search
grid_search = GridSearchCV(
estimator=rf_model,
param_grid=param_grid,
scoring='f1',
cv=3,
verbose=2,
n_jobs=-1
)
# Fit Grid Search
grid_search.fit(X_train, y_train)
# Display the best parameters
print("Best Parameters from Grid Search:")
print(grid_search.best_params_)
Tests all combinations (e.g., 3 × 3 × 2 × 3 = 54 combinations for 3 folds = 162 fits).
Suitable for users with sufficient computational power and time.
Tuning Logistic Regression
For Logistic Regression, key hyperparameters to tune include:
# Define the parameter grid
param_grid_lr = {
'C': [0.01, 0.1, 1, 10],
'penalty': ['l2'],
'solver': ['lbfgs', 'saga']
}
# Initialize Logistic Regression
lr_model = LogisticRegression(max_iter=1000, random_state=42)
# Perform Grid Search
grid_search_lr = GridSearchCV(estimator=lr_model, param_grid=param_grid_lr, scoring='f1', cv=3, verbose=2, n_jobs=-1)
grid_search_lr.fit(X_train, y_train)
# Display the best parameters
print("Best Parameters for Logistic Regression:")
print(grid_search_lr.best_params_)
Fitting 3 folds for each of 8 candidates, totalling 24 fits
Best Parameters for Logistic Regression:
{'C': 10, 'penalty': 'l2', 'solver': 'lbfgs'}
Explanation of Best Parameters
C=10: A higher value ofCreduces the strength of regularization, allowing the model to fit more closely to the training data. This is particularly useful for this dataset, as the model needs flexibility to capture complex patterns.penalty='l2': L2 regularization penalizes large coefficients, reducing the likelihood of overfitting and enhancing generalization.solver='lbfgs': Thelbfgssolver is well-suited for datasets with a large number of samples and features, ensuring efficient optimization.
Performance Comparison (Tuned Models)
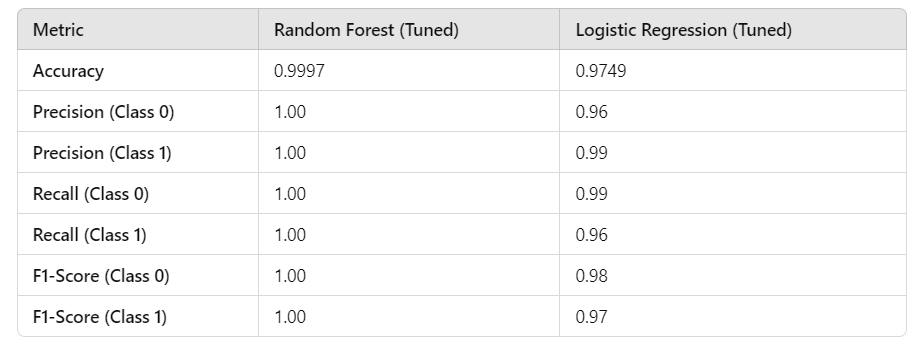
Key Insights:
- Random Forest (Tuned)*:*
Achieves near-perfect performance, with accuracy and F1-score both exceeding 0.999.
Best suited for scenarios where computational resources are available and extremely high accuracy is required.
2. Logistic Regression (Tuned)*:*
Performs well, with an accuracy of 0.9749 and high precision for fraudulent transactions (Class 1).
Provides a viable alternative for resource-constrained settings, with faster training times and competitive performance.
Both models show significant improvements post-tuning, with Random Forest remaining the best performer overall. However, Logistic Regression offers a practical balance of performance and efficiency.
8. Robust Project Pipeline
A robust pipeline streamlines the entire machine learning workflow, making the process more efficient, reusable, and less prone to errors. By encapsulating preprocessing, training, and evaluation steps, we ensure a systematic approach to fraud detection.
Why Use a Pipeline?
Efficiency: Automates repetitive tasks, such as scaling and model fitting, in a single framework.
Reproducibility: Ensures consistent processing of data across different runs or datasets.
Error Prevention: Reduces the risk of mismatched preprocessing steps between training and test data.
Building the Pipeline
We create a pipeline using Pipeline from sklearn.pipeline to integrate feature scaling and model training.
Code:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import RobustScaler
# Random Forest Pipeline
rf_pipeline = Pipeline([
('scaler', RobustScaler()), # Scaling features
('rf', RandomForestClassifier(n_estimators=100, max_depth=20,
min_samples_split=5, max_features='sqrt', random_state=42))
])
# Logistic Regression Pipeline
lr_pipeline = Pipeline([
('scaler', RobustScaler()), # Scaling features
('lr', LogisticRegression(C=10, penalty='l2', solver='lbfgs', max_iter=1000, random_state=42))
])
Training and Evaluating with the Pipeline
The pipeline simplifies the workflow for both training and evaluation by handling preprocessing steps and model fitting seamlessly.
Code:
# Train and evaluate Random Forest pipeline
rf_pipeline.fit(X_train, y_train)
rf_predictions = rf_pipeline.predict(X_test)
print("Random Forest Performance:")
print(classification_report(y_test, rf_predictions))
# Train and evaluate Logistic Regression pipeline
lr_pipeline.fit(X_train, y_train)
lr_predictions = lr_pipeline.predict(X_test)
print("Logistic Regression Performance:")
print(classification_report(y_test, lr_predictions))
Random Forest Performance:
precision recall f1-score support
0 1.00 1.00 1.00 85149
1 1.00 1.00 1.00 85440
accuracy 1.00 170589
macro avg 1.00 1.00 1.00 170589
weighted avg 1.00 1.00 1.00 170589
Logistic Regression Performance:
precision recall f1-score support
0 0.96 0.99 0.98 85149
1 0.99 0.96 0.97 85440
accuracy 0.97 170589
macro avg 0.98 0.97 0.97 170589
weighted avg 0.98 0.97 0.97 170589
The pipeline seamlessly integrates data preprocessing (e.g., scaling) and model training into a single, consistent workflow, ensuring that the same steps are applied to both training and test data. It simplifies the process, reduces manual effort, and minimizes errors while offering flexibility to switch between models, such as Random Forest and Logistic Regression, with minimal adjustments.
For large datasets like creditcard.csv, the pipeline improves scalability and reproducibility, enabling efficient experimentation with different models and hyperparameters. This structured approach lays a solid foundation for deploying the project in real-world applications or extending it with additional features in the future.
9. Conclusions and Next Steps
This project demonstrated a comprehensive approach to credit card fraud detection, leveraging machine learning to address a critical challenge in financial security. Through detailed analysis, we observed that both Random Forest and Logistic Regression models achieved high performance, with Random Forest delivering near-perfect accuracy and Logistic Regression providing a more computationally efficient alternative.
The initial evaluation of all features, including Amount and Time, showed their minimal direct correlation with the target. However, through feature selection, the models focused on the most relevant features, such as V14, V10, and V12, to optimize predictive ability. Random Forest delivered superior accuracy at the cost of higher computational resources, while Logistic Regression provided competitive performance with faster runtimes, making it a practical choice for resource-constrained environments.
Hyperparameter tuning and feature selection played a crucial role in enhancing model performance and refining the models to balance complexity and efficiency. By employing pipelines, the workflow was streamlined, ensuring consistency and reducing manual effort, while also enabling easy experimentation with different models and hyperparameters.
For future work, exploring advanced techniques such as ensemble methods, deep learning models, or real-time fraud detection systems could further improve performance and scalability. Additionally, incorporating feature engineering to derive more meaningful insights from Time and other features could enhance the robustness of the system. This project serves as a strong foundation for building practical fraud detection solutions and advancing personal expertise in machine learning.
Appendix
Code: https://github.com/Minhhoang2606/Credit-card-fraud-detection-by-machine-learning/blob/master/main.py
Data source: https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud




