A/B Testing: The Gold Standard
How verifiable and repeatable experiments drive insight and innovation

Introduction
In the fast-paced world of online services, making informed decisions is crucial for staying ahead. A/B testing stands out as the "gold standard" for achieving this, enabling the creation of verifiable and repeatable experiments. This approach not only accelerates innovation but also ensures that decisions are grounded in solid data rather than mere intuition. By rigorously testing different versions of a product or feature, organizations can identify what truly resonates with their users, leading to continuous improvement and business success. This article delves into the principles, processes, and practical applications of A/B testing, highlighting its significance in today's data-driven landscape.
What is A/B Testing?
A/B tests, also known as controlled experiments, are a method of comparing two or more variants to determine which one performs better. Typically, these variants include a Control (the original experience) and a Treatment (a modified version with a specific change). During an A/B test, users are randomly assigned to either the Control or Treatment group, ensuring an unbiased comparison. User interactions within each group are meticulously tracked and instrumented, generating data that is then analyzed to assess the differences in performance between the variants.
A/B testing goes by many names, including A/B/n tests, field experiments, randomized controlled experiments, split tests, bucket tests, and flights. Regardless of the terminology, the underlying goal remains the same: to gather empirical data that informs decision-making and drives improvements.
The Scientific Method and A/B Testing
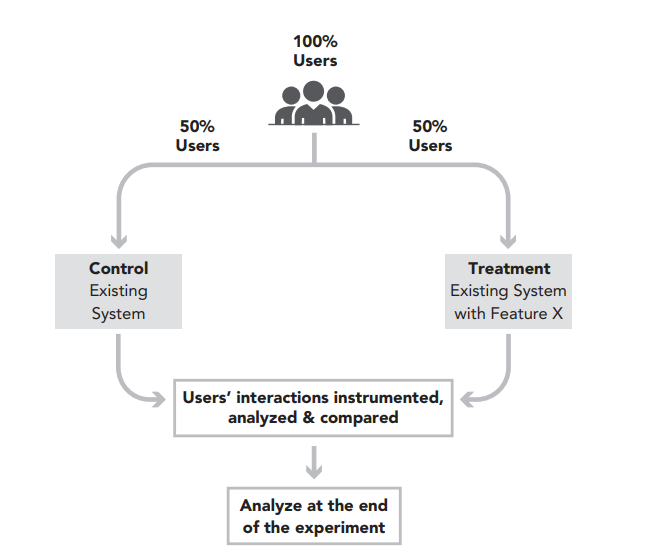
A simple controlled experiment: An A/B Test
At its core, A/B testing embodies the principles of the scientific method. The Lean Methodology emphasizes creating hypotheses, running experiments, gathering data, and extracting actionable insights. A/B testing aligns perfectly with this approach by providing a structured framework for testing hypotheses in a controlled environment. A well-designed A/B test begins with a clear hypothesis that makes specific predictions about the expected outcomes. These predictions are then empirically tested through the experiment, with data collected to either support or refute the initial hypothesis. This iterative process ensures that improvements are based on evidence, fostering a culture of continuous learning and refinement.
Why is A/B Testing Important?
A/B testing offers several key benefits that make it indispensable for modern organizations:
Assess the Value of Ideas:
A/B testing provides a reliable way to assess the value of an idea by measuring its impact on user behavior and key metrics. This is particularly important because it is often difficult to predict the success of an idea without empirical data. For instance, a simple change to the display of ads on Bing was delayed for months, but when implemented, it resulted in over $100 million/year in additional revenue.
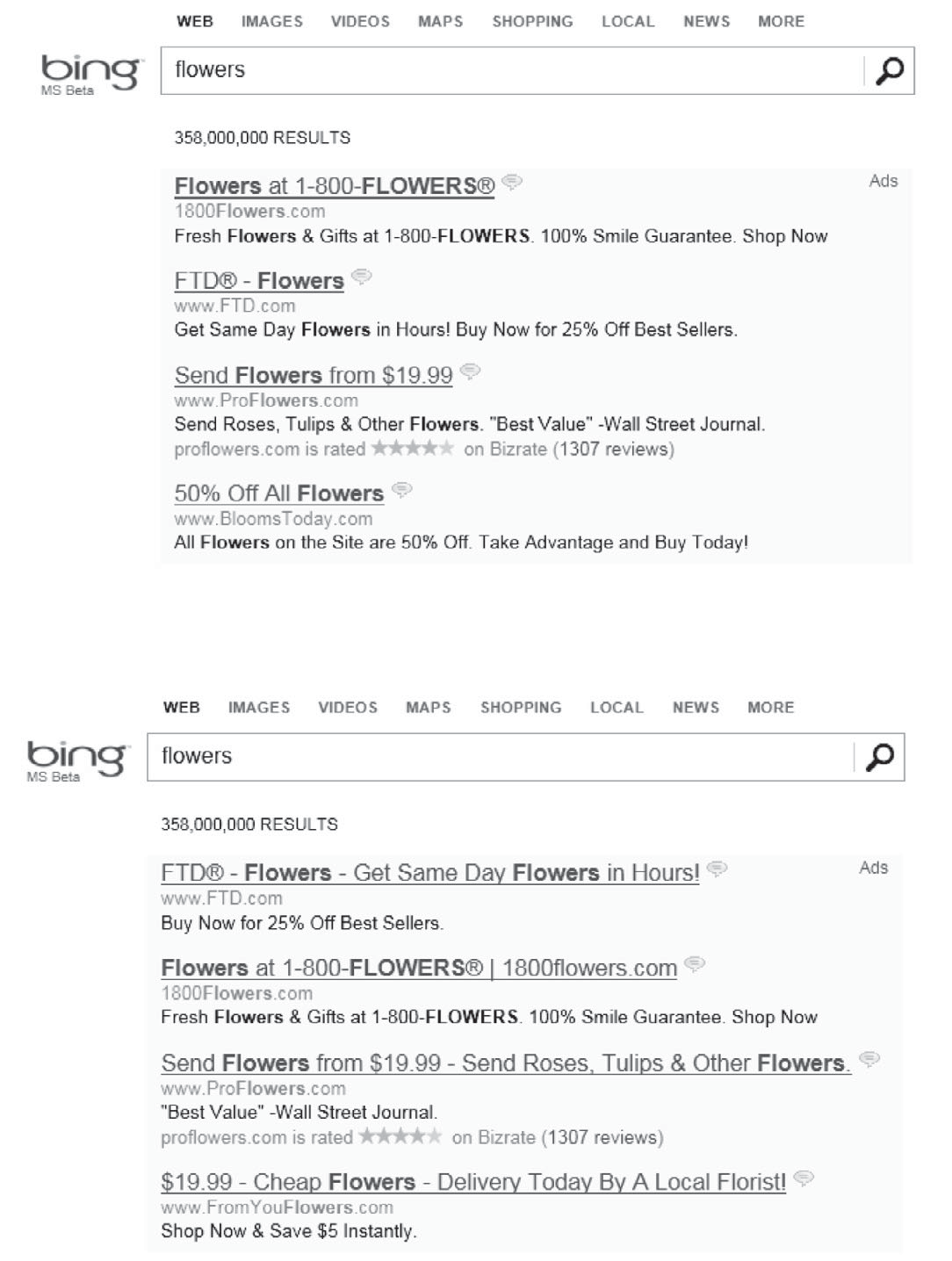
An experiment changing the way ads display on Bing. Source: Trustworthy Online Controlled
Experiments
Small Changes, Big Impact
Even seemingly small changes can have a significant impact on key performance indicators. A $100M/year return-on-investment (ROI) on a few days’ work for one engineer demonstrates the potential of A/B testing to uncover high-value improvements.
Overhead Reduction
To be effective, A/B testing must be conducted with minimal overhead. Building a scalable platform for experimentation can significantly reduce the marginal cost of running tests, making it feasible to test a wide range of ideas.
Clear OEC
A well-defined overall evaluation criterion (OEC) is essential for accurately evaluating the results of an experiment. The OEC should be a quantitative measure that reflects the experiment's objective and aligns with long-term strategic goals. For example, an OEC might be active days per user, indicating increased engagement and value.
Key Components for Running A/B Tests
To conduct successful A/B tests, several key components must be in place:
Hypothesis: Every A/B test should start with a clear hypothesis that predicts the expected outcomes of the experiment. This hypothesis should be specific, measurable, achievable, relevant, and time-bound (SMART).
Metrics: Define key metrics and an Overall Evaluation Criterion (OEC) to measure the experiment's objective. The OEC should be measurable in the short term and drive long-term strategic objectives. Examples of metrics include click-through rate (CTR), conversion rate, and revenue per user.
Experiment Design: Develop a detailed experiment design that outlines the randomization unit, target users, and duration of the test. The randomization unit determines how users are assigned to different variants, while targeting ensures that the experiment reaches the appropriate audience.
Data Collection: Implement robust data collection mechanisms to track user interactions with each variant. This involves instrumenting the system to log relevant events and attributes, ensuring that the data is accurate and reliable.
Analysis: Apply appropriate statistical tests to analyze the data and interpret the results. This includes calculating p-values and confidence intervals to determine the statistical significance of the observed differences between variants.
Ensuring Trustworthiness
The trustworthiness of A/B test results is paramount for making sound decisions. Several factors can threaten the validity of an experiment, and it is crucial to address these to ensure reliable outcomes.
Internal Validity: Threats to internal validity can compromise the integrity of the experiment and lead to inaccurate conclusions.
Sample Ratio Mismatch (SRM): An SRM occurs when the ratio of users between variants deviates significantly from the designed ratio. This can indicate a problem with the experiment setup or data collection process and should be investigated.
Technical Errors: Browser redirects, inaccurate data logging, and inconsistent implementations can also introduce errors that affect the results.
External Validity: External validity refers to the extent to which the results of an experiment can be generalized to other populations and contexts.
Novelty Effects: Introducing a new feature can initially attract users, but this effect may diminish over time if users don't find the feature genuinely useful.
Primacy Effects: These occur when the initial presentation of a feature influences user behavior, regardless of its long-term value.
Segment Differences: Analyzing metrics across different segments can provide valuable insights, but it is important to avoid the pitfalls of Simpson’s paradox. Simpson’s paradox occurs when a trend appears in different groups of data but disappears or reverses when these groups are combined.
Building a Scalable Experimentation Platform
A scalable experimentation platform is essential for organizations that want to run a large number of A/B tests efficiently. Such a platform should include key components for experiment definition, deployment, instrumentation, and analysis.
The experimentation maturity model emphasizes the role of leadership, processes, and training in fostering a culture of experimentation.
A centralized platform makes it easier to capture and organize data, track experiment metadata, and share results across the organization.
Real-World Examples
Numerous real-world examples illustrate the power and potential of A/B testing:
Bing's Title Layout Change: As mentioned earlier, a simple change in ad display on Bing resulted in over $100 million/year in additional revenue.
Amazon's Recommendation Algorithm: Amazon's implementation of the algorithm "People who searched for X bought item Y" increased overall revenue by 3%.
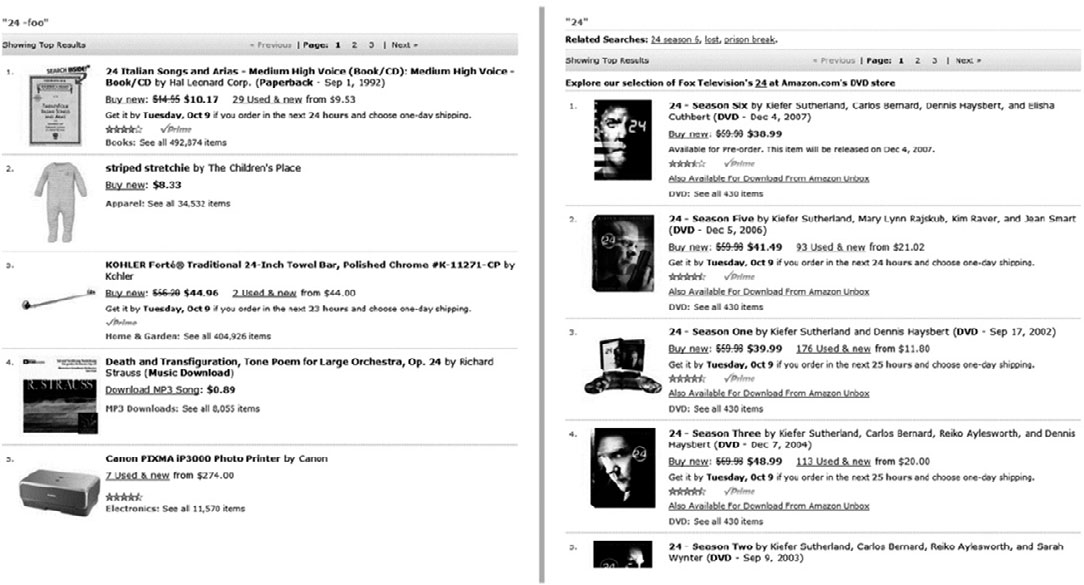
Amazon search for “24” with and without BBS. Source: Trustworthy Online Controlled Experiments
Pitfalls and How to Avoid Them
While A/B testing is a powerful tool, it is essential to be aware of potential pitfalls and take steps to avoid them:
Carryover Effects: Prior experiments can impact subsequent ones, leading to biased results. Re-randomization can mitigate this by ensuring that users are assigned to new variants independently of their previous experiences.
Primacy and Novelty Effects: Initial effects can be misleading, so experiments should run long enough to capture long-term trends. Monitoring usage patterns over time can help detect these effects.
Multiple Hypothesis Testing: When analyzing segments, it is important to correct for multiple hypothesis testing to avoid false positives. Techniques such as Bonferroni correction can help adjust the significance level to account for the number of tests being performed.
The Role of Institutional Memory
Institutional memory, a digital journal of all experiments and changes, is invaluable for continuous improvement.
It reinforces the experiment culture, providing a summary view of past tests.
Meta-analysis identifies best practices and areas for improvement.
Past results guide future innovations and help avoid repeating mistakes.
Conclusion
A/B testing is indeed the gold standard for driving insight and innovation. Its verifiable and repeatable nature ensures data-driven decisions, leading to improved products and a culture of continuous improvement. By implementing A/B testing and taking appropriate precautions, organizations can optimize their online services, achieve business success, and stay ahead in today's competitive landscape.



