
Retaining Subscribers by Machine Learning: How Financial Behaviour Analysis Minimises Churn in Fintech


Table of contents
1. Introduction
In today’s competitive subscription-based landscape, retaining customers is crucial to sustaining business growth and profitability. Churn — the rate at which customers unsubscribe or stop using a service — can significantly impact a company’s revenue, especially for fintech businesses where customer engagement and satisfaction are key drivers of success.
This blog explores a data-driven approach to predicting and minimizing churn by analyzing customer financial habits. Using a fintech subscription product as our case study, we’ll demonstrate how insights from financial behaviours and product usage patterns help identify at-risk customers. By proactively addressing these churn signals, businesses can tailor re-engagement strategies and enhance features that keep customers satisfied and engaged.
Our goal is to create a predictive model that allows for early identification of customers likely to churn, providing actionable insights to improve customer retention. Whether through personalized reminders of product benefits or by developing features that align with user needs, a strong churn prediction model empowers companies to make impactful business decisions.
In the sections that follow, we’ll walk through each step of building this predictive model — from data exploration and feature engineering to model training and evaluation — culminating in a powerful tool for understanding and addressing churn within subscription products.
2. Understanding the Data
To predict churn effectively, we first need to understand the data we’re working with and the behaviours it captures. In this project, we use a dataset from a fintech company that provides a subscription-based financial tracking product. This dataset includes a range of customer information, financial habits, and product usage metrics, which help us identify patterns that may indicate churn risk.
Here are some key variables in the dataset:
userid: A unique identifier for each user, anonymized for privacy.churn: The target variable, indicates whether a user has left the subscription (Yes) or is still active (No).age: The customer’s age, which helps reveal trends based on different age demographics.credit_score: The customer’s credit score, providing insight into financial stability, which may correlate with their likelihood of retaining the service.rent_or_own: A categorical variable indicating if the customer rents or owns their residence, potentially highlighting different financial commitments.payFreq: The frequency with which customers are paid (e.g., monthly, bi-weekly), offering clues about their financial habits.cash_back_engagement: Calculated as the total cash-back amount received divided by the number of days using the app. Higher engagement here may indicate active app use and satisfaction with product benefits.used_iosandused_android: Indicators of whether the customer has used the app on iOS or Android devices, providing insight into device-based usage patterns.has_used_webandhas_used_mobile: Binary indicators of the platforms customers use, which can highlight potential engagement differences between web and mobile users.cards_clicked,cards_helpful,cards_not_helpful: Metrics related to the company’s credit card offerings, capturing user interactions and feedback, which may impact overall satisfaction and likelihood of churn.trivia_played,trivia_shared_results: Engagement with trivia features in the app, showing how interactive content may influence user retention.
The data includes both numeric and categorical variables, as well as several binary indicators (1/0 values), which allow us to gain a holistic view of customer habits and product usage patterns. By analyzing these variables, we can identify trends that are likely to contribute to churn and tailor the predictive model to recognize these risk factors.
With this foundation, the next step involves preparing the data, addressing missing values, and creating new features where necessary. These steps will ensure the model has the best possible information to make accurate predictions on customer churn.
3. Data Preprocessing
Data preprocessing is essential for building a reliable churn prediction model. This phase ensures the data is clean, structured, and ready for analysis. We’ll go through several steps, including loading data, handling missing values, encoding categorical variables, scaling features, and balancing the training set to prepare it for modelling.
Importing Libraries and Loading Data
First, we import the necessary libraries for data manipulation, visualization, and machine learning tasks. Then, we load the dataset, which is stored in a CSV file, into a Pandas DataFrame for easy handling.
# Importing required libraries
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Loading the dataset
dataset = pd.read_csv('churn_data.csv')
dataset.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 27000 entries, 0 to 26999
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user 27000 non-null int64
1 churn 27000 non-null int64
2 age 26996 non-null float64
3 housing 27000 non-null object
4 credit_score 18969 non-null float64
5 deposits 27000 non-null int64
6 withdrawal 27000 non-null int64
7 purchases_partners 27000 non-null int64
8 purchases 27000 non-null int64
9 cc_taken 27000 non-null int64
10 cc_recommended 27000 non-null int64
11 cc_disliked 27000 non-null int64
12 cc_liked 27000 non-null int64
13 cc_application_begin 27000 non-null int64
14 app_downloaded 27000 non-null int64
15 web_user 27000 non-null int64
16 app_web_user 27000 non-null int64
17 ios_user 27000 non-null int64
18 android_user 27000 non-null int64
19 registered_phones 27000 non-null int64
20 payment_type 27000 non-null object
21 waiting_4_loan 27000 non-null int64
22 cancelled_loan 27000 non-null int64
23 received_loan 27000 non-null int64
24 rejected_loan 27000 non-null int64
25 zodiac_sign 27000 non-null object
26 left_for_two_month_plus 27000 non-null int64
27 left_for_one_month 27000 non-null int64
28 rewards_earned 23773 non-null float64
29 reward_rate 27000 non-null float64
30 is_referred 27000 non-null int64
dtypes: float64(4), int64(24), object(3)
memory usage: 6.4+ MB
Handling Missing Values
The first step in preprocessing is identifying and handling missing values.
# Indentify missing values
dataset.isna().sum()
user 0
churn 0
age 4
housing 0
credit_score 8031
deposits 0
withdrawal 0
purchases_partners 0
purchases 0
cc_taken 0
cc_recommended 0
cc_disliked 0
cc_liked 0
cc_application_begin 0
app_downloaded 0
web_user 0
app_web_user 0
ios_user 0
android_user 0
registered_phones 0
payment_type 0
waiting_4_loan 0
cancelled_loan 0
received_loan 0
rejected_loan 0
zodiac_sign 0
left_for_two_month_plus 0
left_for_one_month 0
rewards_earned 3227
reward_rate 0
is_referred 0
dtype: int64
In our dataset, some columns have missing values, which can affect model performance if not addressed. We removed rows with missing values in the age column, as the count was minimal. However, columns like credit_score and rewards_earned had a high percentage of missing values, so we dropped these columns to avoid biases in the analysis.
# Dropping columns with high missing values
dataset.drop(columns=['credit_score', 'rewards_earned'], inplace=True)
# Dropping rows with missing values in 'age'
dataset = dataset[dataset['age'].notna()]
4. Exploratory Data Analysis (EDA)
Exploratory Data Analysis (EDA) helps us understand the patterns and relationships in our data, providing critical insights that inform feature selection, engineering, and model-building decisions. This section’ll explore key trends, distributions, and correlations that may impact customer churn.
Analyzing Numerical Features’ Distributions
To start, we will analyze the distribution of all numerical features in the dataset. This includes both integer and float columns, excluding the user column since it represents a nominal identifier rather than a meaningful numerical feature. By plotting histograms for each of these features, we can observe their distributions and identify any patterns or outliers that may inform our analysis.
The following code generates histograms for each relevant numerical feature in the dataset:
## Plotting histograms for numerical features
import matplotlib.pyplot as plt
# List of numerical features excluding 'user'
numerical_features = ['churn', 'age', 'deposits', 'withdrawal', 'purchases_partners',
'purchases', 'cc_taken', 'cc_recommended', 'cc_disliked', 'cc_liked',
'cc_application_begin', 'app_downloaded', 'web_user', 'app_web_user',
'ios_user', 'android_user', 'registered_phones', 'waiting_4_loan',
'cancelled_loan', 'received_loan', 'rejected_loan', 'left_for_two_month_plus',
'left_for_one_month', 'reward_rate', 'is_referred']
# Number of columns and rows for the layout
n_cols = 5
n_rows = (len(numerical_features) + n_cols - 1) // n_cols # Calculate required rows
# Create the figure and axes
fig, axes = plt.subplots(n_rows, n_cols, figsize=(20, 15))
fig.suptitle("Distribution of Numerical Features", fontsize=20)
# Flatten axes array for easier iteration
axes = axes.flatten()
# Plot each feature in a separate subplot
for i, feature in enumerate(numerical_features):
if feature in dataset.columns: # Ensure the feature exists in the dataset
axes[i].hist(dataset[feature].dropna(), bins=20, edgecolor='black') # Drop NA values for cleaner plots
axes[i].set_title(feature)
else:
axes[i].text(0.5, 0.5, f"{feature} not found", ha='center', va='center')
axes[i].axis('off')
plt.tight_layout(rect=[0, 0, 1, 0.96]) # Adjust layout to fit the main title
plt.show()
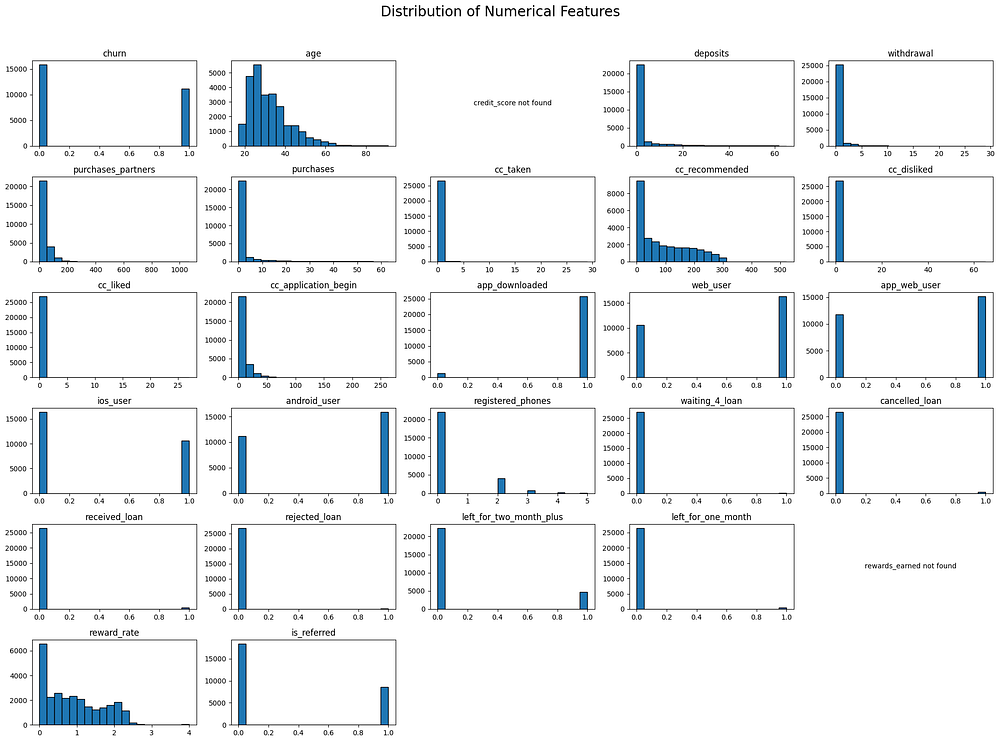
The histograms show the distribution patterns of various numerical features in the dataset:
Binary Features: Many features, like
churn,app_downloaded,web_user,ios_user,android_user, and other loan-related features, have binary distributions (values of 0 and 1), indicating whether a user has taken a particular action or status.Right-Skewed Features: Features like
age,deposits,withdrawal,purchases,cc_taken,cc_recommended,cc_application_begin, andpurchases_partnersare right-skewed, with most values concentrated at the lower end of the scale. This indicates that the majority of users have low engagement in these areas.Categorical Features with More Categories: Features like
registered_phonesandpayment_typeshow a small spread across different categories, with certain values (like 0 forregistered_phonesand Bi-Weekly forpayment_type) being much more common.Reward-related Features:
reward_rateshows a wider distribution, indicating varying levels of rewards earned by users, whilerewards_earnedwas not found in the dataset, so its distribution isn’t shown.
Overall, most non-binary features have right-skewed distributions, while binary features clearly indicate user behaviour or characteristics through their two-value structure.
Analyzing Categorical Variables
We analyze each categorical variable in the dataset using pie charts to understand the distribution of categories within each feature. Many of these categorical features are binary, represented as integers (0 and 1), where 1 typically signifies the presence of a characteristic, and 0 signifies its absence. This approach allows us to visualize the proportion of users in each category and gain insights into user behaviours.
The following categorical variables are analyzed:
Binary Features (0 and 1): Many features, such as
is_referred,app_downloaded,web_user,app_web_user,ios_user,android_user, and others, are binary. These features use1to indicate a positive response or engagement (e.g., the app was downloaded, and the user accessed the website), while0indicating no engagement or lack of the characteristic. Pie charts are used to illustrate the percentage of users in each category, providing insight into the proportion of engaged users.Housing: This feature shows whether a user rents, owns, or has missing housing data. Housing type could influence financial stability and engagement with the product.
Registered Phones: This feature indicates the number of phones registered by each user, providing insight into engagement level or user commitment.
Payment Type: The
payment_typevariable represents the frequency of income (e.g., weekly, biweekly). Understanding the distribution of income frequency may help in analyzing spending and product usage behaviours.Loan Status (waiting, cancelled, received, rejected): These features represent various loan statuses, indicating whether a user is waiting for a loan, or has cancelled, received, or rejected a loan. The distribution of each status may reflect user satisfaction and financial activity.
Zodiac Sign: This feature includes zodiac signs, allowing us to explore if any unique behavioural patterns exist among different zodiac groups.
Inactivity Status (left for one month or two months plus): These variables indicate if a user was inactive for one month or more than two months. High inactivity rates could be a sign of disengagement.
Below is the code to generate pie charts for each categorical variable, including binary features represented by integers:
import matplotlib.pyplot as plt
# List of categorical features
categorical_features = ['housing', 'is_referred', 'app_downloaded',
'web_user', 'app_web_user', 'ios_user',
'android_user', 'registered_phones', 'payment_type',
'waiting_4_loan', 'cancelled_loan',
'received_loan', 'rejected_loan', 'zodiac_sign',
'left_for_two_month_plus', 'left_for_one_month', 'is_referred']
# Plotting pie charts for each categorical variable
for feature in categorical_features:
values_counts = dataset[feature].value_counts()
plt.figure(figsize=(6, 6))
plt.pie(values_counts, labels=values_counts.index, autopct='%1.1f%%', startangle=140)
plt.title(f"Distribution of {feature}")
plt.show()
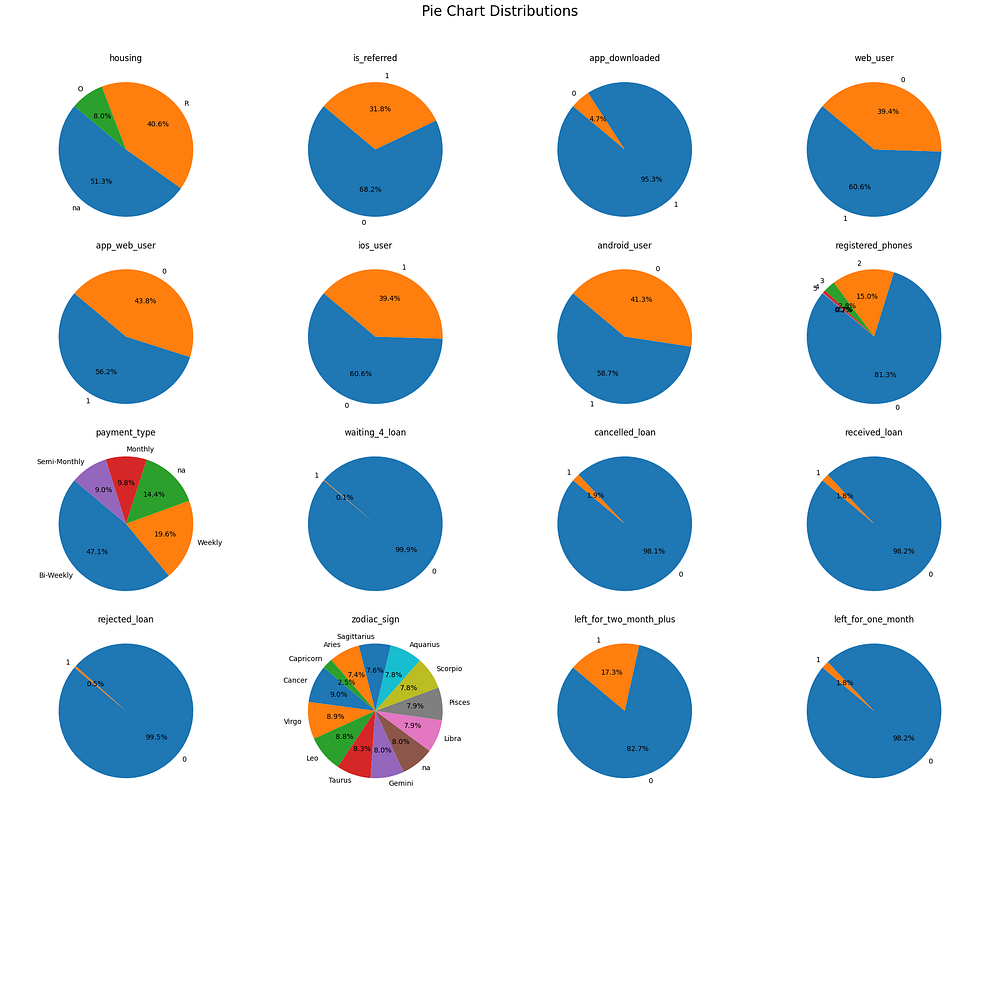
Housing: Over half of the users’ housing status is unknown (51.3%), with 40.6% renting and 8.0% owning.
Referral Status: Most users (68.2%) were not referred, with 31.8% having been referred by others.
App Downloaded: A vast majority (95.3%) have downloaded the app, indicating high mobile engagement.
Web User: 60.6% have used the website, while 39.4% have not.
App & Web User: 56.2% have used both app and web platforms, suggesting a multi-platform preference for many users.
iOS vs. Android Users: 60.6% are iOS users, and 58.7% are Android users, showing a slight overlap.
Registered Phones: Most users (81.3%) have registered only one phone, with a minority registering multiple phones.
Payment Type: Most users are on a bi-weekly payment schedule (47.1%), followed by weekly (19.6%) and monthly (14.4%).
Loan Statuses: Waiting: Almost no users are currently waiting for a loan; Cancelled: 98.1% have never cancelled a loan; Received: 98.2% have never received a loan; Rejected: 99.5% have not rejected a loan.
Zodiac Sign: Evenly distributed across signs, with no clear dominance by any sign.
Inactivity: Left for Two Months Plus: 17.3% have been inactive for over two months; Left for One Month: Only 1.8% were inactive for one month.
In the pie chart analysis of categorical variables, several features are binary (e.g., is_referred, app_downloaded, web_user, ios_user, android_user, waiting_4_loan, rejected_loan, etc.), showing distributions primarily split between 0 and 1 values. For binary columns, a balanced distribution can provide more robust insights for modelling, as it allows for better differentiation between churn and non-churn behaviours. When distributions are highly imbalanced, such as in waiting_4_loan and rejected_loan, the model may struggle to learn from the minority class, potentially impacting its predictive power in similar real-world cases. A balanced distribution, or at least a significant representation of both values, is crucial for understanding nuanced customer behaviours that contribute to churn risk.
This analysis highlights high mobile app usage, a bi-weekly payment preference, and a majority of users without loan activity. Inactivity is relatively low, but some users show long-term disengagement.
Relationship with the Target Variable (Churn)
In this section, we’ll explore the relationship between selected key features and the target variable, churn. By analyzing these relationships, we aim to understand which factors are more likely to influence users to leave the service. We’ll use a bar chart to visualize the correlation coefficients of each feature with churn. Positive correlations (bars above the x-axis) suggest that as the feature value increases, so does the likelihood of churn. Negative correlations (bars below the x-axis) indicate that higher feature values are associated with a lower likelihood of churn.
Selected Features for Analysis
Age: Age differences can impact user engagement patterns and thus affect churn. Younger and older users might interact differently with the service.
Deposits and Withdrawals: These features measure user financial activity. Users with more deposits and withdrawals might be more engaged and less likely to churn.
Purchases and Purchases with Partners: These features provide insight into users’ spending behaviour within and outside of partner stores. Increased spending within the service ecosystem could indicate loyalty.
CC Recommended / CC Taken: These features indicate user interest in additional products offered by the service, such as credit cards. A higher interest may correlate with lower churn.
App Downloaded / Web User: These binary features show if users engage with the service through the app or website. Users who downloaded the app or engaged on the web may have a higher likelihood of remaining active.
Reward Rate: This feature captures user engagement with rewards programs. Users who frequently earn rewards may feel more engaged and less likely to churn.
Registered Phones: Users who registered more devices might interact with the service across multiple devices, indicating higher engagement and a lower risk of churn.
Correlation with Target Variable Analysis
The bar chart below visualizes the correlation of each selected feature with churn. The chart helps us identify which features have stronger associations with the likelihood of users unsubscribing.
import matplotlib.pyplot as plt
# Calculate correlation values for selected features
selected_features = ['age', 'deposits', 'withdrawal', 'purchases_partners', 'purchases',
'cc_taken', 'cc_recommended', 'app_downloaded', 'web_user',
'reward_rate', 'registered_phones']
correlations = dataset[selected_features + ['churn']].corr()['churn'].drop('churn')
# Plotting the correlations with churn
plt.figure(figsize=(10, 6))
correlations.plot(kind='bar', color=['blue' if val > 0 else 'orange' for val in correlations])
plt.title('Correlation of Selected Features with Churn')
plt.xlabel('Features')
plt.ylabel('Correlation with Churn')
plt.axhline(0, color='black', linewidth=0.5)
plt.xticks(rotation=45)
plt.show()
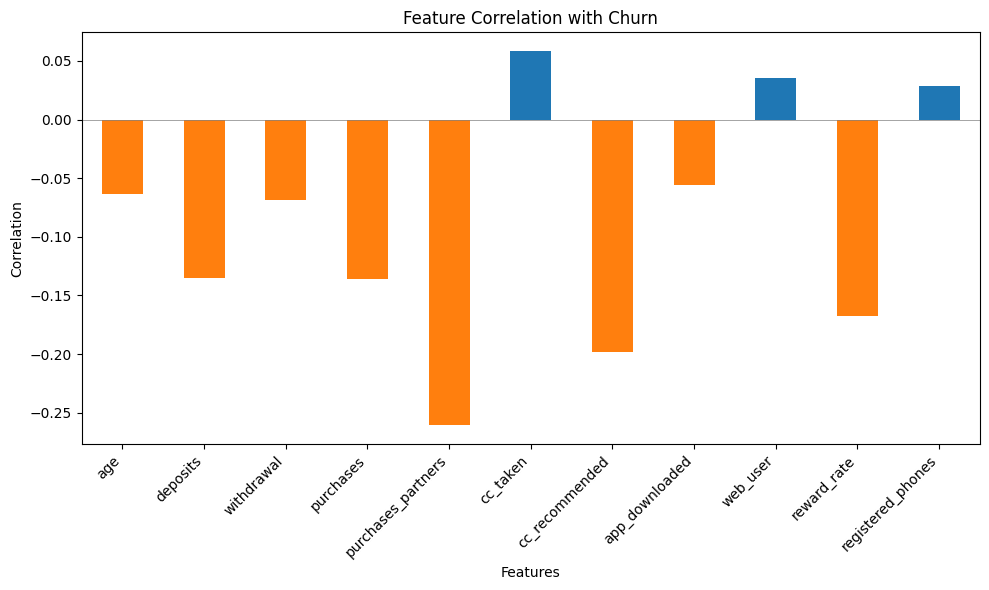
This bar chart shows the correlation between selected features and churn. Features like purchases_partners, reward_rate, and withdrawal have strong negative correlations, indicating that higher values in these features are associated with lower churn rates. In contrast, cc_taken, web_user, and cc_recommended have positive correlations, suggesting that users engaging with these aspects might have a slightly higher likelihood of churning. The overall insight is that financial engagement and rewards tend to reduce churn, while certain service recommendations may not appeal strongly to users at risk of leaving.
Correlation Matrix
In this section, we explore the correlation matrix to identify relationships among the numerical features, particularly those that may have strong associations with the target variable (churn). The correlation matrix allows us to see both positive and negative correlations, helping us understand feature interactions and identify any multicollinearity that may need attention.
Generating the Correlation Matrix
We calculate the correlation matrix for all numerical features and visualize it using a heatmap. This will help us pinpoint features that have strong positive or negative relationships with each other and with the churn variable.
# Compute the correlation matrix
corr_matrix = dataset.corr()
# Plotting the heatmap
plt.figure(figsize=(12, 10))
sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap='coolwarm', center=0, linewidths=1)
plt.title("Correlation Matrix of Numerical Features")
plt.show()
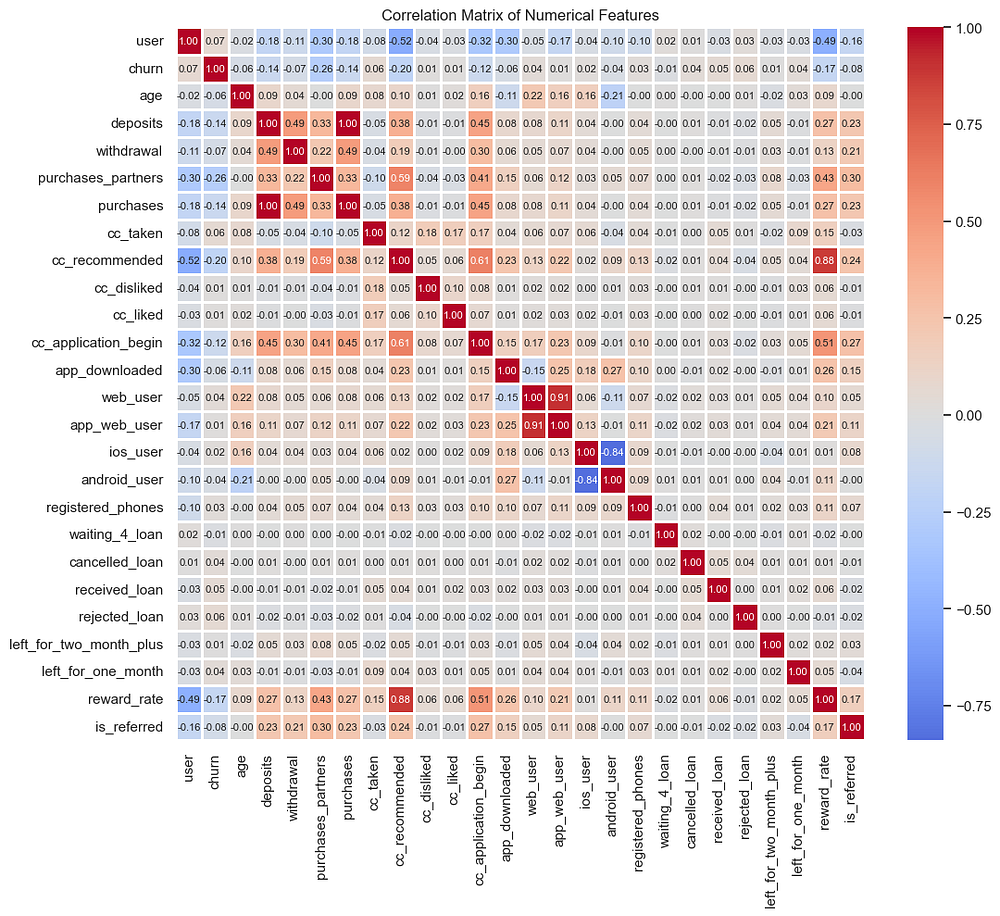
The correlation matrix provides valuable insights into the relationships between different features and helps guide feature selection for modelling. Here are the key takeaways:
High Correlation Features for Dropping:
The
depositsfeature exhibits a perfect correlation withpurchases(1.0), indicating complete redundancy. To avoid multicollinearity and simplify the model, we will dropdepositsfrom the dataset.Similarly,
app_web_usershows a high correlation withweb_user(0.91). Since both features provide similar information, we will dropapp_web_userthem to reduce redundancy.
# Dropping highly correlated features
dataset = dataset.drop(['deposits', 'app_web_user'], axis=1)
Notable Correlations with churn:
purchases_partners(-0.26) andreward_rate(-0.24) have moderate negative correlations withchurn, suggesting that as engagement in partner purchases and reward rates increase, churn decreases. These features may provide valuable insights for churn prediction.cc_taken(-0.14) andwithdrawal(-0.10) also show smaller negative correlations withchurn, indicating a potential inverse relationship.
Potential Multicollinearity:
- Other strong correlations, such as between
cc_likedandcc_recommended(0.88), suggests the need for careful consideration of feature combinations to avoid redundancy in modelling.
By addressing redundancy through feature dropping and focusing on features with meaningful correlations to churn, we aim to improve model performance and interpretability.
5. Feature Engineering
In this step, we prepare our dataset for modelling by defining our target variable (y) and feature set (X). We also drop the highly correlated features we identified earlier: deposits, due to its perfect correlation with purchases, and app_web_user, due to its high correlation with web_user.
Define the Target (y) and Features (X)
Our target variable, churn, represents customer churn, and our feature set consists of all other columns. Here’s how we define X and y:
# Define the dependent variable (target) y
y = dataset['churn']
# Define the independent variables (features) X by dropping the target column
X = dataset.drop(['churn'], axis=1)
Handling Categorical Variables by One-Hot Encoding
First, we apply one-hot encoding to convert categorical variables into binary vectors. This step is performed on the entire dataset to ensure consistent feature alignment between the training and test sets.
# Apply one-hot encoding to categorical features
dataset = pd.get_dummies(dataset, columns=['housing', 'payment_type', 'zodiac_sign'], drop_first=True)
Splitting the Dataset
We split the dataset into training and test sets, with 80% of the data used for training and 20% for testing. This split allows us to evaluate the model’s performance on unseen data.
from sklearn.model_selection import train_test_split
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Balancing the Dataset
To avoid bias in the model, we balanced the training dataset by oversampling the minority class to match the majority class. This step is essential to improve model accuracy on both classes (churned and non-churned).
from imblearn.over_sampling import SMOTE
# Apply SMOTE to balance the training set
smote = SMOTE(random_state=42)
X_train, y_train = smote.fit_resample(X_train, y_train)
Feature Scaling
Finally, we scale the numerical features to ensure they have a mean of zero and a standard deviation of one. Scaling is fitted on the training set and then applied to both the training and test sets to prevent data leakage.
# Feature Scaling
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
numerical_features = ['age', 'credit_score', 'withdrawal', 'purchases_partners',
'purchases', 'reward_rate', 'registered_phones']
# Fit on the training set, then transform both training and test sets
X_train[numerical_features] = scaler.fit_transform(X_train[numerical_features])
X_test[numerical_features] = scaler.transform(X_test[numerical_features])Through these steps, we have prepared a dataset that is now ready for model building, with balanced classes, encoded categorical features, and scaled numerical values. These modifications are aimed at improving model performance and ensuring fair treatment across feature values.
This completes the feature engineering process, ensuring the data is ready for model training and evaluation.
6. Model Building and Evaluation
In this section, we implement and evaluate our initial model. Our approach involves using an object-oriented framework to streamline repetitive tasks, specifically model training, K-Fold Cross-Validation, and calculating the confusion matrix.
To make the evaluation process more efficient, we created a ModelEvaluator class, which includes methods for training, evaluating with K-Fold Cross-Validation, and calculating a confusion matrix. This setup allows us to reuse these methods for any model, including those built with feature selection techniques.
# Importing Libraries
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, cross_val_score, cross_val_predict
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.feature_selection import RFE
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
from imblearn.over_sampling import SMOTE
# Load Data
dataset = pd.read_csv('processed_churn_data.csv')
# Define the independent variables X and dependent variable y
X = dataset.drop(columns=['churn'])
y = dataset['churn']
# Apply one-hot encoding to categorical features
X = pd.get_dummies(X, columns=['housing', 'payment_type', 'zodiac_sign'], drop_first=True)
# Split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Balance the training set using SMOTE
smote = SMOTE(random_state=42)
X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)
# Standardize numerical features
scaler = StandardScaler()
numerical_features = ['age', 'withdrawal', 'purchases_partners', 'purchases', 'reward_rate', 'registered_phones']
X_train_smote[numerical_features] = scaler.fit_transform(X_train_smote[numerical_features])
X_test[numerical_features] = scaler.transform(X_test[numerical_features])
# Define the ModelEvaluator class for repeated steps
class ModelEvaluator:
def __init__(self, model, X, y, cv=10):
"""
Initialize the ModelEvaluator with a classifier, features, target, and cross-validation folds.
"""
self.model = model
self.X = X
self.y = y
self.cv = cv
def k_fold_cross_validation(self):
"""
Perform K-Fold Cross-Validation and print the mean accuracy.
"""
accuracies = cross_val_score(estimator=self.model, X=self.X, y=self.y, cv=self.cv)
print("Mean Accuracy: {:.3f} (+/- {:.3f})".format(accuracies.mean(), accuracies.std() * 2))
return accuracies
def calculate_confusion_matrix(self):
"""
Calculate and print the confusion matrix and other performance metrics.
"""
y_pred = cross_val_predict(self.model, self.X, self.y, cv=self.cv)
conf_matrix = confusion_matrix(self.y, y_pred)
# Extract and display metrics
accuracy = accuracy_score(self.y, y_pred)
precision = precision_score(self.y, y_pred)
recall = recall_score(self.y, y_pred)
f1 = f1_score(self.y, y_pred)
print("Confusion Matrix:\n", conf_matrix)
print("Accuracy: {:.2f}".format(accuracy))
print("Precision: {:.2f}".format(precision))
print("Recall: {:.2f}".format(recall))
print("F1 Score: {:.2f}".format(f1))
return conf_matrix, accuracy, precision, recall, f1
# Initialize the logistic regression model
classifier = LogisticRegression()
# Evaluate the original model
print("Original Model Evaluation:")
evaluator = ModelEvaluator(classifier, X_train_smote, y_train_smote)
evaluator.k_fold_cross_validation()
evaluator.calculate_confusion_matrix()
Original Model Evaluation:
Confusion Matrix:
[[6995 5673]
[3030 9638]]
Accuracy: 0.66
Precision: 0.63
Recall: 0.76
F1 Score: 0.69
With this setup, we have completed both training and evaluation. Using the ModelEvaluator class, we performed K-Fold Cross-Validation and confusion matrix evaluation in a structured way, ready to be reused with more refined models.
The original model shows an accuracy of 66%, indicating that it correctly classified 66% of all cases. With a precision of 63%, it identified 63% of positive predictions accurately. A recall of 76% suggests the model captured 76% of actual positives. The F1 score of 0.69 balances precision and recall, reflecting a reasonably effective model, though there’s room for improvement, especially in precision.
7. Improving Model Performance with K-Fold Cross-Validation and Recursive Feature Elimination (RFE)
We introduce Recursive Feature Elimination (RFE) to further improve model performance to identify and retain only the most impactful features. We re-train and evaluate the model with the reduced feature set, using our ModelEvaluator class to ensure consistency and streamline the comparison with the initial model.
RFE helps identify features that contribute the most to the model, improving its generalization. Here’s how we implement RFE with the Logistic Regression model:
from sklearn.feature_selection import RFE
# Apply Recursive Feature Elimination (RFE)
rfe = RFE(estimator=classifier, n_features_to_select=20)
X_train_rfe = rfe.fit_transform(X_train_smote, y_train_smote)
X_test_rfe = rfe.transform(X_test)
# Training the Model with Selected Features
classifier_rfe = LogisticRegression(random_state=42)
classifier_rfe.fit(X_train_rfe, y_train_smote)
# Evaluate the RFE model
print("\nRFE Model Evaluation:")
rfe_evaluator = ModelEvaluator(classifier, X_train_rfe, y_train_smote)
rfe_evaluator.k_fold_cross_validation()
rfe_evaluator.calculate_confusion_matrix()
RFE Model Evaluation:
Mean Accuracy: 0.671 (+/- 0.128)
Confusion Matrix:
[[7605 5063]
[3265 9403]]
Accuracy: 0.67
Precision: 0.65
Recall: 0.74
F1 Score: 0.69
The RFE model delivers a similar performance to the original model with a mean accuracy of 67% and an F1 score of 0.69. While these improvements in accuracy and F1 are modest, the RFE method notably reduces computational demands by focusing only on the most impactful features. This reduction in features not only enhances model efficiency but also saves significant computational resources since it uses only 20 features instead of 41 features as the original model, making it more scalable for larger datasets or real-time applications. This streamlined model can lead to substantial cost savings and faster processing times, adding a valuable business benefit by optimizing resource allocation without sacrificing model effectiveness.
8. Conclusions and Business Impacts
In this project, we developed a predictive model to identify customers at risk of churn, based on an analysis of financial habits and product engagement. By systematically processing and analyzing customer data, we were able to highlight significant features impacting churn and implement a predictive model using both standard logistic regression and Recursive Feature Elimination (RFE) for improved performance.
The model achieved:
Accuracy: 67%
Precision: 65%
Recall: 74%
F1 Score: 0.69
These metrics indicate a moderately effective model, particularly valuable for identifying a substantial portion of customers likely to churn, with the recall rate of 74% highlighting its capacity to correctly identify actual churn cases. Though modest, the model’s precision and F1 score represent a balanced ability to make reliable predictions without excessive false positives, thus aligning with a practical business application.
Business Benefits and Insights:
Targeted Interventions: By accurately predicting at-risk customers, the model allows the business to proactively engage these users, potentially through customized offers, retention strategies, or incentives. This can lead to improved customer satisfaction and retention, minimizing revenue loss from customer churn.
Efficient Resource Allocation: The RFE model retained similar performance metrics while using fewer features, significantly reducing computational demands. This streamlined model is more efficient and cost-effective for large-scale or real-time applications, making it practical for continuous deployment in production environments.
Strategic Product Development: Insights from the model reveal which product interactions (e.g., purchases, credit card engagement) and user demographics correlate with churn. Understanding these patterns enables the business to optimize or expand offerings that better align with customer preferences, increasing the overall value of the product.
Future Model Improvement: While the model provides valuable predictions, introducing a time component could allow predictions of churn within specific timeframes, refining the model’s actionable insights. This would support further customization in engagement strategies based on the urgency of predicted churn.
In conclusion, this project demonstrates the power of data-driven churn prediction. With potential cost savings, targeted customer retention, and strategic product development, the model offers substantial value by aligning predictive insights with actionable business strategies, ultimately supporting the company’s growth and customer satisfaction goals.
Appendix
Data source: https://www.kaggle.com/datasets/rishisharma/churn-dataset